filmov
tv
python encoding error with utf 8

Показать описание
Python supports various character encodings, and UTF-8 is one of the most widely used. However, working with UTF-8 encoding can sometimes lead to encoding errors, especially when dealing with different character sets. This tutorial aims to explain common Python encoding errors related to UTF-8 and provides solutions with code examples.
Unicode is a standardized character encoding that assigns a unique number (code point) to every character in almost every writing system. It provides a way to represent text in any writing system in a consistent manner.
UTF-8 is one of the encoding schemes used to represent Unicode characters. It uses variable-length encoding, meaning different characters may require a different number of bytes to represent.
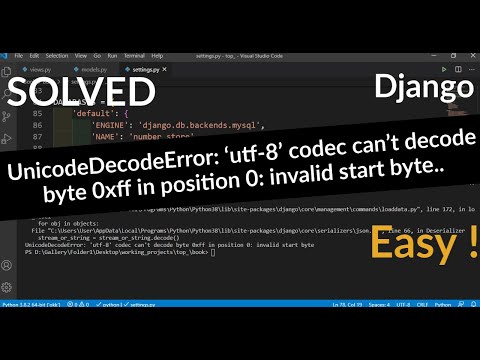
This error occurs when trying to decode a byte sequence into a string using an incorrect encoding. UTF-8 is commonly used, but if the byte sequence doesn't follow UTF-8 rules, decoding will fail.
This error happens when trying to encode a string into bytes using an incorrect encoding. Again, if the string contains characters that cannot be represented in the specified encoding (e.g., UTF-8), encoding will fail.
Always specify the encoding explicitly when working with text files, streams, or byte sequences.
When decoding, you can handle errors by specifying the errors parameter.
Understanding and handling encoding errors is crucial when working with text data in Python, especially when using UTF-8. By following the guidelines and examples in this tutorial, you can write robust code that gracefully handles encoding issues. Always remember to explicitly specify the encoding and handle errors appropriately to ensure your code works seamlessly with diverse character sets.
ChatGPT
Unicode is a standardized character encoding that assigns a unique number (code point) to every character in almost every writing system. It provides a way to represent text in any writing system in a consistent manner.
UTF-8 is one of the encoding schemes used to represent Unicode characters. It uses variable-length encoding, meaning different characters may require a different number of bytes to represent.
This error occurs when trying to decode a byte sequence into a string using an incorrect encoding. UTF-8 is commonly used, but if the byte sequence doesn't follow UTF-8 rules, decoding will fail.
This error happens when trying to encode a string into bytes using an incorrect encoding. Again, if the string contains characters that cannot be represented in the specified encoding (e.g., UTF-8), encoding will fail.
Always specify the encoding explicitly when working with text files, streams, or byte sequences.
When decoding, you can handle errors by specifying the errors parameter.
Understanding and handling encoding errors is crucial when working with text data in Python, especially when using UTF-8. By following the guidelines and examples in this tutorial, you can write robust code that gracefully handles encoding issues. Always remember to explicitly specify the encoding and handle errors appropriately to ensure your code works seamlessly with diverse character sets.
ChatGPT
 0:09:40
0:09:40
 0:00:59
0:00:59
 0:02:58
0:02:58
 0:06:50
0:06:50
 0:01:16
0:01:16
 0:03:29
0:03:29
 0:01:16
0:01:16
 0:02:04
0:02:04
 0:02:16
0:02:16
 0:00:52
0:00:52
 0:01:31
0:01:31
 0:03:41
0:03:41
 0:01:18
0:01:18
 0:06:05
0:06:05
 0:02:21
0:02:21
 0:10:54
0:10:54
 0:01:29
0:01:29
 0:01:45
0:01:45
 0:00:54
0:00:54
 0:14:34
0:14:34
 0:01:00
0:01:00
 0:00:59
0:00:59
 0:03:19
0:03:19
 0:01:15
0:01:15