filmov
tv
Unicode, in friendly terms: ASCII, UTF-8, code points, character encodings, and more

Показать описание
Ever been bit by a Unicode bug? Maybe you weren't treating UTF-8 encoded data correctly, or tried to read it as ASCII? Maybe you mixed up UTF-8 vs UTF-16? Unicode and character encoding might seem like a tricky topic, but let's break them down and learn about them piece by piece, from ASCII to code points to graphemes to combining character modifiers and more.
00:00 Intro
00:12 All Data Is Stored As Bits
00:41 How To Store Characters Using ASCII
01:38 What About All The Other Languages?
02:14 Graphemes Map To One Or More Code Points
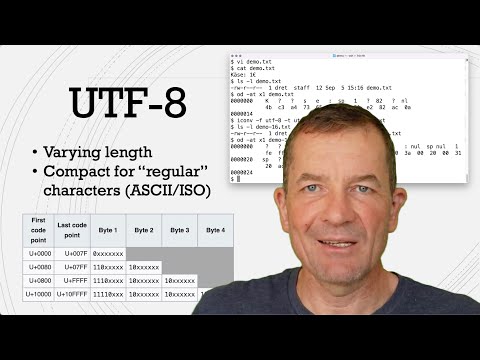
03:18 Code Points Map To One Or More Bytes
03:44 UTF-32 Is Wasteful
04:43 UTF-8 Is Better
05:40 Unicode is Western-Language-Centric
06:41 Mid-Video Recap
07:52 Live Python Demo
09:47 Unicode Rules Of Thumb
10:14 Looking At A Code Point
00:00 Intro
00:12 All Data Is Stored As Bits
00:41 How To Store Characters Using ASCII
01:38 What About All The Other Languages?
02:14 Graphemes Map To One Or More Code Points
03:18 Code Points Map To One Or More Bytes
03:44 UTF-32 Is Wasteful
04:43 UTF-8 Is Better
05:40 Unicode is Western-Language-Centric
06:41 Mid-Video Recap
07:52 Live Python Demo
09:47 Unicode Rules Of Thumb
10:14 Looking At A Code Point
 0:10:54
0:10:54
Unicode, in friendly terms: ASCII, UTF-8, code points, character encodings, and more
 0:03:29
0:03:29
ASCII, Unicode, UTF-8: Explained Simply
 0:14:36
0:14:36
Understanding text for C Programmers (UTF-8, Unicode, ASCII)
 0:09:37
0:09:37
Characters, Symbols and the Unicode Miracle - Computerphile
 0:09:43
0:09:43
Understanding Text Encoding in Go: ASCII, Unicode, and utf-8 Explained
 0:10:41
0:10:41
ASCII, Unicode, UTF-32, UTF-8 explained | Examples in Rust, Go, Python
 0:03:31
0:03:31
Unicode 1: What means: ASCII, ANSI, Code Page
 0:09:37
0:09:37
What are UTF-8 and UTF-16? Working with Unicode encodings
 0:29:03
0:29:03
Unicode, UTF 8 and ASCII
 0:00:07
0:00:07
this Unicode character is impossible to type 😱😱😱😱😱
 0:05:45
0:05:45
⍼ - Why Nobody Knows What This One Unicode Character Means
 0:19:07
0:19:07
Ep 020: Unicode Code Points and UTF-8 Encoding
 0:05:06
0:05:06
ASCII, Extended ASCII and Unicode | 9618 | AS Level Computer Science
 0:17:18
0:17:18
Code Pages, Character Encoding, Unicode, UTF-8 and the BOM - Computer Stuff They Didn't Teach Y...
 0:07:36
0:07:36
What is Unicode? How does it work and how do you use it?
 0:00:40
0:00:40
Unicode be like: Episode 1
 0:05:04
0:05:04
What Is Unicode? And Why Do I Need To Use Unicode?
 0:05:35
0:05:35
ASCII, UNICODE et UTF8 - Spé NSI - Première Informatique
 0:01:30
0:01:30
Data Representation - ASCII vs Unicode
 0:10:22
0:10:22
C# Tutorial - Basic - 031 - Character encoding & Unicode
 0:20:39
0:20:39
Unicode in Rust - Illustrated by Kanji - Jenny Manning
 0:09:42
0:09:42
ASCii and Unicode Questions
 0:06:50
0:06:50
C# Programming Tutorial 15 - Char Data Type and ASCII Unicode
 0:59:40
0:59:40
CppCon 2014: James McNellis 'Unicode in C++'
Комментарии