filmov
tv
Understanding UTF-8 Encoding and Decoding in Python

Показать описание
Disclaimer/Disclosure: Some of the content was synthetically produced using various Generative AI (artificial intelligence) tools; so, there may be inaccuracies or misleading information present in the video. Please consider this before relying on the content to make any decisions or take any actions etc. If you still have any concerns, please feel free to write them in a comment. Thank you.
---
Summary: Discover how to handle UTF-8 encoding and decoding in Python, from converting strings to byte format and back. Learn more about `encode` and `decode` methods in simple examples.
---
Understanding UTF-8 Encoding and Decoding in Python
Python provides robust support for Unicode, making it easier to work with international text and special characters. One of the common encoding formats is UTF-8, which stands for "Unicode Transformation Format - 8-bit". This post will guide you through the basics of UTF-8 encoding and decoding in Python.
What is UTF-8?
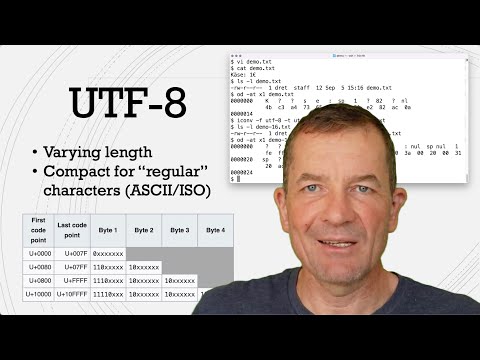
UTF-8 is a variable-width character encoding standard that can represent every character in the Unicode character set. It is backward-compatible with ASCII, which means that any ASCII text is also valid UTF-8 encoded text.
Encoding with UTF-8 in Python
The encode method in Python allows you to convert a string into bytes using any specified encoding format, including UTF-8.
Example:
[[See Video to Reveal this Text or Code Snippet]]
In this example, the string text contains both ASCII and non-ASCII characters (the earth emoji). By using the encode('utf-8') method, we convert the string into a bytes object.
Decoding with UTF-8 in Python
Similarly, the decode method converts bytes back into a string. This is useful when reading text data from files or network sources that are encoded in UTF-8.
Example:
[[See Video to Reveal this Text or Code Snippet]]
Here, we take the previously encoded byte object and decode it back into a string using decode('utf-8').
Error Handling
Encoding and decoding processes can run into errors, especially when the text contains characters not supported by the chosen encoding scheme. Python offers different error handling schemes to manage such situations.
Common Error Handlers:
strict (default): Raises an error if there is an encoding/decoding issue.
ignore: Ignores invalid characters.
replace: Replaces invalid characters with a placeholder (usually ? for encoding).
Example:
[[See Video to Reveal this Text or Code Snippet]]
Conclusion
In this post, we explored the basics of UTF-8 encoding and decoding in Python. We learned how to use the encode and decode methods and how to handle errors during these processes. Understanding how encoding and decoding work is fundamental for handling text data, especially when dealing with multiple languages and special characters.
By mastering these basics, you are better equipped to manage text data in your Python applications efficiently.
---
Summary: Discover how to handle UTF-8 encoding and decoding in Python, from converting strings to byte format and back. Learn more about `encode` and `decode` methods in simple examples.
---
Understanding UTF-8 Encoding and Decoding in Python
Python provides robust support for Unicode, making it easier to work with international text and special characters. One of the common encoding formats is UTF-8, which stands for "Unicode Transformation Format - 8-bit". This post will guide you through the basics of UTF-8 encoding and decoding in Python.
What is UTF-8?
UTF-8 is a variable-width character encoding standard that can represent every character in the Unicode character set. It is backward-compatible with ASCII, which means that any ASCII text is also valid UTF-8 encoded text.
Encoding with UTF-8 in Python
The encode method in Python allows you to convert a string into bytes using any specified encoding format, including UTF-8.
Example:
[[See Video to Reveal this Text or Code Snippet]]
In this example, the string text contains both ASCII and non-ASCII characters (the earth emoji). By using the encode('utf-8') method, we convert the string into a bytes object.
Decoding with UTF-8 in Python
Similarly, the decode method converts bytes back into a string. This is useful when reading text data from files or network sources that are encoded in UTF-8.
Example:
[[See Video to Reveal this Text or Code Snippet]]
Here, we take the previously encoded byte object and decode it back into a string using decode('utf-8').
Error Handling
Encoding and decoding processes can run into errors, especially when the text contains characters not supported by the chosen encoding scheme. Python offers different error handling schemes to manage such situations.
Common Error Handlers:
strict (default): Raises an error if there is an encoding/decoding issue.
ignore: Ignores invalid characters.
replace: Replaces invalid characters with a placeholder (usually ? for encoding).
Example:
[[See Video to Reveal this Text or Code Snippet]]
Conclusion
In this post, we explored the basics of UTF-8 encoding and decoding in Python. We learned how to use the encode and decode methods and how to handle errors during these processes. Understanding how encoding and decoding work is fundamental for handling text data, especially when dealing with multiple languages and special characters.
By mastering these basics, you are better equipped to manage text data in your Python applications efficiently.
 0:10:54
0:10:54
 0:03:29
0:03:29
 0:09:37
0:09:37
 0:14:34
0:14:34
 0:09:37
0:09:37
 0:19:07
0:19:07
 0:04:13
0:04:13
 0:01:31
0:01:31
 0:00:52
0:00:52
 0:24:52
0:24:52
 0:05:59
0:05:59
 0:10:41
0:10:41
 0:29:03
0:29:03
 0:08:48
0:08:48
 0:01:54
0:01:54
 0:01:10
0:01:10
 0:11:06
0:11:06
 0:15:31
0:15:31
 0:11:15
0:11:15
 0:04:12
0:04:12
 0:03:01
0:03:01
 0:03:15
0:03:15
 0:03:33
0:03:33
 0:07:15
0:07:15