filmov
tv
OpenAI CLIP Explained | Multi-modal ML

Показать описание
OpenAI's CLIP explained simply and intuitively with visuals and code. Language models (LMs) can not rely on language alone. That is the idea behind the "Experience Grounds Language" paper, that proposes a framework to measure LMs' current and future progress. A key idea is that, beyond a certain threshold LMs need other forms of data, such as visual input.
The next step beyond well-known language models; BERT, GPT-3, and T5 is "World Scope 3". In World Scope 3, we move from large text-only datasets to large multi-modal datasets. That is, datasets containing information from multiple forms of media, like *both* images and text.
The world, both digital and real, is multi-modal. We perceive the world as an orchestra of language, imagery, video, smell, touch, and more. This chaotic ensemble produces an inner state, our "model" of the outside world.
AI must move in the same direction. Even specialist models that focus on language or vision must, at some point, have input from the other modalities. How can a model fully understand the concept of the word "person" without *seeing* a person?
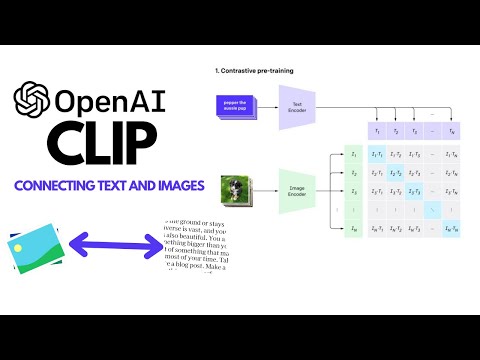
OpenAI's Contrastive Learning In Pretraining (CLIP) is a world scope three model. It can comprehend concepts in both text and image and even connect concepts between the two modalities. In this video we will learn about multi-modality, how CLIP works, and how to use CLIP for different use cases like encoding, classification, and object detection.
🌲 Pinecone article:
🤖 70% Discount on the NLP With Transformers in Python course:
🎉 Subscribe for Article and Video Updates!
👾 Discord:
The next step beyond well-known language models; BERT, GPT-3, and T5 is "World Scope 3". In World Scope 3, we move from large text-only datasets to large multi-modal datasets. That is, datasets containing information from multiple forms of media, like *both* images and text.
The world, both digital and real, is multi-modal. We perceive the world as an orchestra of language, imagery, video, smell, touch, and more. This chaotic ensemble produces an inner state, our "model" of the outside world.
AI must move in the same direction. Even specialist models that focus on language or vision must, at some point, have input from the other modalities. How can a model fully understand the concept of the word "person" without *seeing* a person?
OpenAI's Contrastive Learning In Pretraining (CLIP) is a world scope three model. It can comprehend concepts in both text and image and even connect concepts between the two modalities. In this video we will learn about multi-modality, how CLIP works, and how to use CLIP for different use cases like encoding, classification, and object detection.
🌲 Pinecone article:
🤖 70% Discount on the NLP With Transformers in Python course:
🎉 Subscribe for Article and Video Updates!
👾 Discord:
 0:33:33
0:33:33
OpenAI CLIP Explained | Multi-modal ML
 0:48:07
0:48:07
OpenAI CLIP: ConnectingText and Images (Paper Explained)
 0:22:54
0:22:54
Fast intro to multi-modal ML with OpenAI's CLIP
 0:14:48
0:14:48
OpenAI’s CLIP explained! | Examples, links to code and pretrained model
 0:09:25
0:09:25
CLIP: Connecting Text and Images
 0:35:19
0:35:19
Supercharge eCommerce Search: OpenAI's CLIP, BM25, and Python
 0:06:44
0:06:44
How do Multimodal AI models work? Simple explanation
 0:32:00
0:32:00
OpenAI's CLIP Explained and Implementation | Contrastive Learning | Self-Supervised Learning
 0:59:27
0:59:27
Domain-Specific Multi-Modal Machine Learning with CLIP
 0:29:32
0:29:32
Fast Zero Shot Object Detection with OpenAI CLIP
 0:21:43
0:21:43
OpenAI's CLIP for Zero Shot Image Classification
 0:31:40
0:31:40
OpenAI CLIP: Connecting Text and Images
 0:58:41
0:58:41
Various CLIP Creative Models Exploration (1/3) [OpenAI CLIP]
 0:03:16
0:03:16
OpenAI CLIP SImilar Image Search
 0:51:30
0:51:30
Multimodal Neurons in Artificial Neural Networks (w/ OpenAI Microscope, Research Paper Explained)
 1:30:40
1:30:40
OpenAI CLIP | Machine Learning Coding Series
 0:22:03
0:22:03
Multi-modal RAG With LANGCHAIN 🦜🔗 & GPT-4V
 0:01:23
0:01:23
Say hello to GPT-4o
 0:11:58
0:11:58
Image Search in Python with OpenAI CLIP
 0:07:51
0:07:51
Computer vision levels up with OpenAI’s CLIP
 1:26:56
1:26:56
Searching Across Images and Text: Intro to OpenAI’s CLIP
 0:53:09
0:53:09
CLIP, DALL E, Multimodal Neurons
 0:08:28
0:08:28
OpenAI CLIP Guided Diffusion - Make images from text!
 0:10:02
0:10:02
OpenAI Releases CLIP | A New AI Model That Can Identify Objects and Scenes in Images!
Комментарии