filmov
tv
OpenAI CLIP: ConnectingText and Images (Paper Explained)
Показать описание
#ai #openai #technology
Paper Title: Learning Transferable Visual Models From Natural Language Supervision
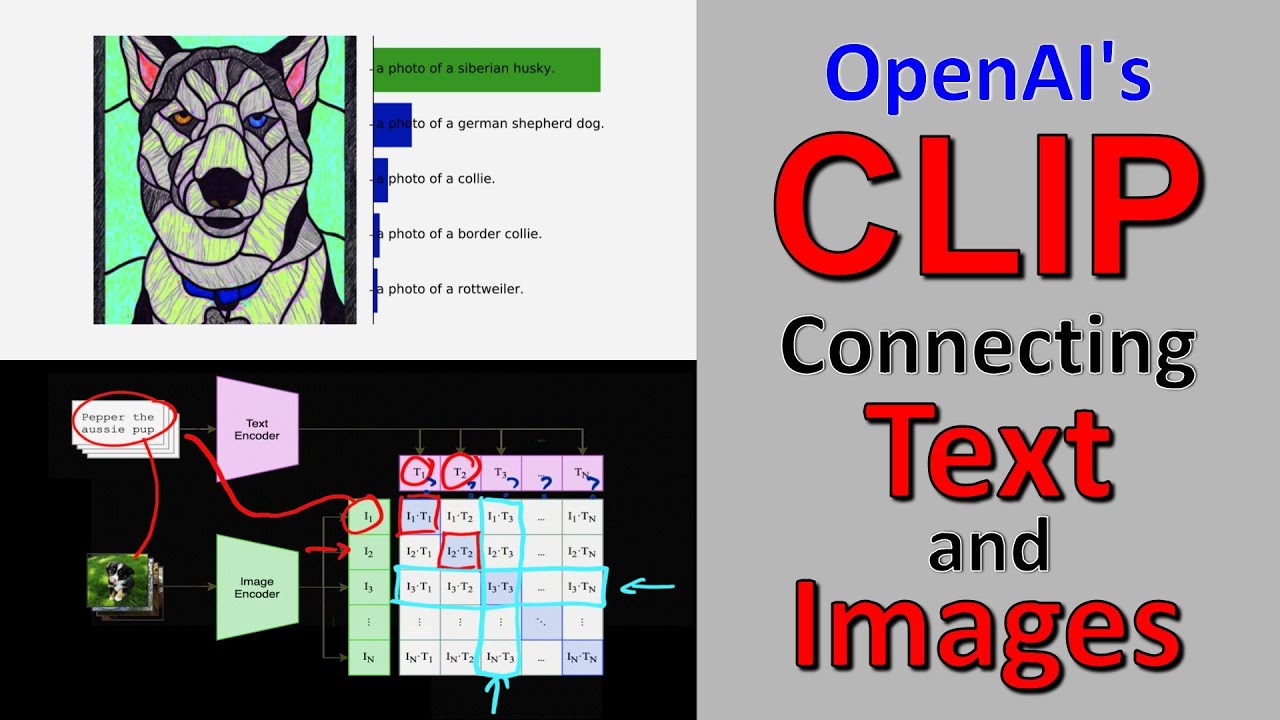
CLIP trains on 400 million images scraped from the web, along with text descriptions to learn a model that can connect the two modalities. The core idea is a contrastive objective combined with a large batch size. The resulting model can be turned into arbitrary zero-shot classifiers for new image & text tasks.
OUTLINE:
0:00 - Introduction
3:15 - Overview
4:40 - Connecting Images & Text
9:00 - Building Zero-Shot Classifiers
14:40 - CLIP Contrastive Training Objective
22:25 - Encoder Choices
25:00 - Zero-Shot CLIP vs Linear ResNet-50
31:50 - Zero-Shot vs Few-Shot
35:35 - Scaling Properties
36:35 - Comparison on different tasks
37:40 - Robustness to Data Shift
44:20 - Broader Impact Section
47:00 - Conclusion & Comments
Abstract:
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on.
Authors: Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
Links:
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Paper Title: Learning Transferable Visual Models From Natural Language Supervision
CLIP trains on 400 million images scraped from the web, along with text descriptions to learn a model that can connect the two modalities. The core idea is a contrastive objective combined with a large batch size. The resulting model can be turned into arbitrary zero-shot classifiers for new image & text tasks.
OUTLINE:
0:00 - Introduction
3:15 - Overview
4:40 - Connecting Images & Text
9:00 - Building Zero-Shot Classifiers
14:40 - CLIP Contrastive Training Objective
22:25 - Encoder Choices
25:00 - Zero-Shot CLIP vs Linear ResNet-50
31:50 - Zero-Shot vs Few-Shot
35:35 - Scaling Properties
36:35 - Comparison on different tasks
37:40 - Robustness to Data Shift
44:20 - Broader Impact Section
47:00 - Conclusion & Comments
Abstract:
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on.
Authors: Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
Links:
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
 0:48:07
0:48:07
OpenAI CLIP: ConnectingText and Images (Paper Explained)
 0:09:25
0:09:25
CLIP: Connecting Text and Images
 0:31:40
0:31:40
OpenAI CLIP: Connecting Text and Images
 0:04:51
0:04:51
CLIP: Connecting text and images
 0:32:00
0:32:00
OpenAI's CLIP Explained and Implementation | Contrastive Learning | Self-Supervised Learning
 0:22:54
0:22:54
Fast intro to multi-modal ML with OpenAI's CLIP
 0:21:43
0:21:43
OpenAI's CLIP for Zero Shot Image Classification
 0:33:33
0:33:33
OpenAI CLIP Explained | Multi-modal ML
 1:26:56
1:26:56
Searching Across Images and Text: Intro to OpenAI’s CLIP
 0:08:29
0:08:29
CLIP: OpenAI's amazing new zero-shot image classifier
 0:14:48
0:14:48
OpenAI’s CLIP explained! | Examples, links to code and pretrained model
 0:06:31
0:06:31
Categorize images Using OpenAI’s CLIP in RunwayML
 0:07:51
0:07:51
Computer vision levels up with OpenAI’s CLIP
 0:11:58
0:11:58
Image Search in Python with OpenAI CLIP
 0:08:02
0:08:02
Finetune Like You Pretrain: Robust finetuning of CLIP
 0:20:50
0:20:50
CLIP: Connecting Text and Images
 0:29:32
0:29:32
Fast Zero Shot Object Detection with OpenAI CLIP
 0:08:25
0:08:25
How to run OpenAI CLIP with UI for Image Retrieval and Filtering your dataset | CV tutorial
 1:30:40
1:30:40
OpenAI CLIP | Machine Learning Coding Series
 0:01:27
0:01:27
*AI Art* - 'CLIP' Visualized - (Contrastive Language-Image Pre-training)
 0:07:18
0:07:18
CLIP: OpenAI’s image-classification model
 0:02:01
0:02:01
Unveiling the Future: OpenAI CLIP Revolutionizes Image Search and Beyond!
 0:20:52
0:20:52
CLIP, T-SNE, and UMAP - Master Image Embeddings & Vector Analysis
 0:10:02
0:10:02
OpenAI Releases CLIP | A New AI Model That Can Identify Objects and Scenes in Images!
Комментарии