filmov
tv
CLIP: Connecting Text and Images

Показать описание
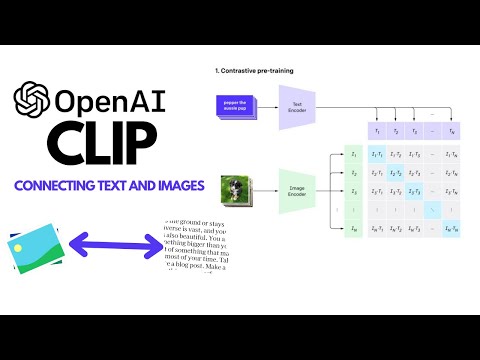
This video explains how CLIP from OpenAI transforms Image Classification into a Text-Image similarity matching task. This is done with Contrastive Training and Zero-Shot Pattern-Exploiting Training. Thanks for watching!
Paper Links:
Thanks for watching! Please Subscribe!
Paper Links:
Thanks for watching! Please Subscribe!
 0:04:51
0:04:51
CLIP: Connecting text and images
 0:48:07
0:48:07
OpenAI CLIP: ConnectingText and Images (Paper Explained)
 0:09:25
0:09:25
CLIP: Connecting Text and Images
 0:31:40
0:31:40
OpenAI CLIP: Connecting Text and Images
 0:20:50
0:20:50
CLIP: Connecting Text and Images
 0:58:04
0:58:04
Ariel Ekgren: CLIP: Connecting text and images
 0:44:37
0:44:37
CLIP: Connecting Text and Images (Swedish NLP Webinars)
 0:03:00
0:03:00
Multilingual CLIP - Connecting images and texts in 100 languages
 0:14:48
0:14:48
OpenAI’s CLIP explained! | Examples, links to code and pretrained model
 0:32:00
0:32:00
OpenAI's CLIP Explained and Implementation | Contrastive Learning | Self-Supervised Learning
 0:22:54
0:22:54
Fast intro to multi-modal ML with OpenAI's CLIP
 0:02:28
0:02:28
Introducing CLIP OpenAI's AI Model Connecting Images and Text
 1:26:56
1:26:56
Searching Across Images and Text: Intro to OpenAI’s CLIP
 0:14:01
0:14:01
CLIP - Paper explanation (training and inference)
 0:21:43
0:21:43
OpenAI's CLIP for Zero Shot Image Classification
 0:20:52
0:20:52
CLIP, T-SNE, and UMAP - Master Image Embeddings & Vector Analysis
 0:38:18
0:38:18
CLIP model
 0:07:39
0:07:39
Connecting Images to Text: CLIP and DALL-E | NLP Journal Club
 0:06:35
0:06:35
What CLIP models are (Contrastive Language-Image Pre-training)
 0:12:36
0:12:36
How to Implement CLIP AI: A Step-by-Step Tutorial for Beginners
 1:13:22
1:13:22
Contrastive Language-Image Pre-training (CLIP)
 2:03:00
2:03:00
DigitalFUTURES Tutorial: Creative AI Text to Image with VQGAN+CLIP
 0:08:29
0:08:29
CLIP: OpenAI's amazing new zero-shot image classifier
 0:23:47
0:23:47
How does CLIP Text-to-image generation work?
Комментарии