filmov
tv
OpenAI CLIP: Connecting Text and Images

Показать описание
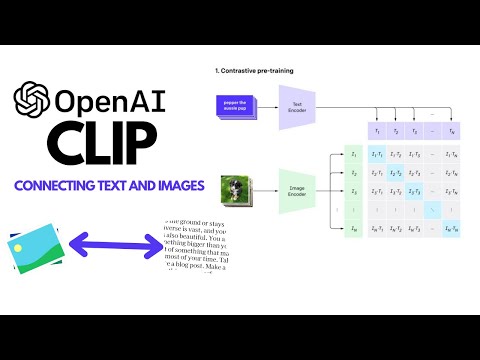
CLIP is a model that connects Text and Images. It has been pre-trained using 400 million (image, text) pairs for task of predicting which caption goes with which image. CLIP can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized, similar to the “zero-shot” capabilities of GPT-2 and GPT-3.
It has been tested on 30+ CV tasks like OCR, action recognition in videos, geo-localization, etc. zero-shot CLIP is often equivalent to fully supervised baseline. E.g., 0-shot CLIP is equivalent to ResNet-50 with 1.28M train set on ImageNet. Eight models show smooth accuracy improvements with scale.
In this video, I will briefly provide an overview of CLIP, its pretraining data, its pretraining architecture. We will also talk about its zero-shot performance, robustness to distribution shifts, and comparison to human performance.
Here is the agenda:
00:00:00 What is OpenAI CLIP?
00:02:09 What is contrastive pretraining? And why?
00:05:20 What dataset was used for contrastive pretraining?
00:06:30 What is the architecture of CLIP models?
00:08:38 How is CLIP used for zero-shot classification?
00:12:02 How does 0-shot CLIP perform compared to equivalent supervised classifier?
00:17:36 How do CLIP representations perform compared to other ImageNet trained representations?
00:19:46 CLIP’s robustness to Natural Distribution Shifts
00:21:23 Comparison to Human Performance
00:23:58 Bias
00:27:38 Image classification examples.
Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry et al. "Learning transferable visual models from natural language supervision." In International Conference on Machine Learning, pp. 8748-8763. PMLR, 2021.
It has been tested on 30+ CV tasks like OCR, action recognition in videos, geo-localization, etc. zero-shot CLIP is often equivalent to fully supervised baseline. E.g., 0-shot CLIP is equivalent to ResNet-50 with 1.28M train set on ImageNet. Eight models show smooth accuracy improvements with scale.
In this video, I will briefly provide an overview of CLIP, its pretraining data, its pretraining architecture. We will also talk about its zero-shot performance, robustness to distribution shifts, and comparison to human performance.
Here is the agenda:
00:00:00 What is OpenAI CLIP?
00:02:09 What is contrastive pretraining? And why?
00:05:20 What dataset was used for contrastive pretraining?
00:06:30 What is the architecture of CLIP models?
00:08:38 How is CLIP used for zero-shot classification?
00:12:02 How does 0-shot CLIP perform compared to equivalent supervised classifier?
00:17:36 How do CLIP representations perform compared to other ImageNet trained representations?
00:19:46 CLIP’s robustness to Natural Distribution Shifts
00:21:23 Comparison to Human Performance
00:23:58 Bias
00:27:38 Image classification examples.
Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry et al. "Learning transferable visual models from natural language supervision." In International Conference on Machine Learning, pp. 8748-8763. PMLR, 2021.
 0:48:07
0:48:07
OpenAI CLIP: ConnectingText and Images (Paper Explained)
 0:31:40
0:31:40
OpenAI CLIP: Connecting Text and Images
 0:09:25
0:09:25
CLIP: Connecting Text and Images
 0:04:51
0:04:51
CLIP: Connecting text and images
 0:14:48
0:14:48
OpenAI’s CLIP explained! | Examples, links to code and pretrained model
 0:33:33
0:33:33
OpenAI CLIP Explained | Multi-modal ML
 0:20:50
0:20:50
CLIP: Connecting Text and Images
 0:32:00
0:32:00
OpenAI's CLIP Explained and Implementation | Contrastive Learning | Self-Supervised Learning
 0:22:54
0:22:54
Fast intro to multi-modal ML with OpenAI's CLIP
 0:21:43
0:21:43
OpenAI's CLIP for Zero Shot Image Classification
 0:12:08
0:12:08
OpenAI CLIP model explained
 1:30:40
1:30:40
OpenAI CLIP | Machine Learning Coding Series
 1:26:56
1:26:56
Searching Across Images and Text: Intro to OpenAI’s CLIP
 0:12:36
0:12:36
How to Implement CLIP AI: A Step-by-Step Tutorial for Beginners
 0:02:28
0:02:28
Introducing CLIP OpenAI's AI Model Connecting Images and Text
 0:21:50
0:21:50
Mastering OpenAI CLIP Model & Practical Usage Tutorial
 0:58:04
0:58:04
Ariel Ekgren: CLIP: Connecting text and images
 0:08:29
0:08:29
CLIP: OpenAI's amazing new zero-shot image classifier
 0:44:37
0:44:37
CLIP: Connecting Text and Images (Swedish NLP Webinars)
 0:11:58
0:11:58
Image Search in Python with OpenAI CLIP
 0:07:51
0:07:51
Computer vision levels up with OpenAI’s CLIP
 0:58:41
0:58:41
Various CLIP Creative Models Exploration (1/3) [OpenAI CLIP]
 0:39:02
0:39:02
Experimental Films + Machine Learning Week 7 Part 1 (Aphantasia with OpenAI CLIP)
 0:29:32
0:29:32
Fast Zero Shot Object Detection with OpenAI CLIP
Комментарии