filmov
tv
Understanding UTF and UCS in C++: The Ultimate Guide for Unicode Handling

Показать описание
Explore the essential differences between `UTF` and `UCS` in C++, discover the best practices for string representation, storage, and transport formats to handle non-European character sets seamlessly.
---
Visit these links for original content and any more details, such as alternate solutions, comments, revision history etc. For example, the original title of the Question was: UTF usage in C++ code
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Understanding UTF and UCS in C++: The Ultimate Guide for Unicode Handling
In today's globalized world, it's essential for software applications to support diverse character sets. As a C++ developer, you might encounter scenarios where you need to manipulate strings that contain a variety of characters beyond the typical European alphabets. This leads us to a critical question: What is the difference between UTF and UCS, and how can we effectively represent non-European character sets in C++?
In this guide, we will break down the answers to these questions while providing practical recommendations for internal representation, storage, and wire transport formats.
What are UTF and UCS?
Before diving into implementation strategies, let's clarify the distinction between UTF (Unicode Transformation Format) and UCS (Universal Character Set):
UCS
Fixed Width: UCS encodings use a fixed number of bytes per character. For example, UCS-2 uses 2 bytes for each character.
Limitations: Characters that fall outside the defined range cannot be represented in UCS encodings.
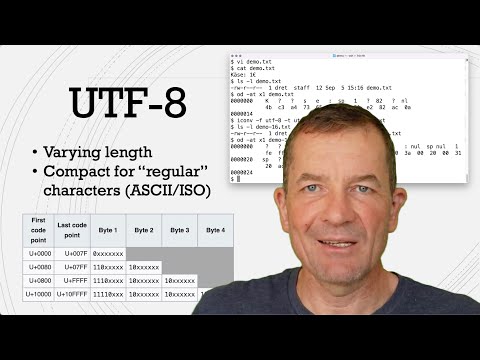
UTF
Variable Width: UTF encodings provide a flexible approach where the number of bytes used can vary. For instance, UTF-16 requires at least 16 bits (or 2 bytes) for a character but may use 4 bytes for characters with more complex code points.
Flexibility: This format allows for a wider range of characters to be encoded.
Recommendations for C++ String Representation
Now that we've established the key differences between UTF and UCS, let's explore practical ways to represent non-European character sets in C++ effectively.
1. Internal Representation Inside the Code
The choice of internal string representation in your C++ application greatly depends on the platform you are using. Here are the common practices:
Windows: Generally, UTF-16 is the preferred internal representation. This format accommodates most characters in the Basic Multilingual Plane (BMP) efficiently, requiring less memory compared to UCS-4.
UNIX: UCS-4 is commonly used. This offers simplicity and allows better manipulation because each character has a consistent size.
Important Considerations:
Memory Usage:
UTF-16 strings use memory effectively for larger texts primarily composed of BMP characters.
UCS-4 simplifies string processing because string characters maintain a consistent representation, eliminating confusion arising from surrogate pairs present in UTF-16.
Interoperability: Some systems may implement UTF-8 internally, which is beneficial for maintaining compatibility with ASCII or ISO-8859 systems since it avoids NULL bytes mid-string, unlike UTF-16 or UCS-4.
2. Best Storage Representation
When it comes to storing your character data, UTF-8 is the recommended encoding. This standard is widely used and efficient for text files:
Advantages of UTF-8:
It compresses characters effectively, especially for texts that consist predominantly of ASCII characters.
It is highly compatible with most modern software systems.
3. Best On-Wire Transport Format
For data transfers between applications, especially across different architectures, UTF-8 also stands out as the optimal transport format due to its flexibility and robustness:
Compatibility: It adheres to the conventions of modern data transmission protocols, mitigating issues with character alignment that can occur with fixed-width formats like UCS.
Efficiency: Reduces the overhead when dealing with non-ASCII data, ensuring smooth interoperability between systems.
Conclusion
Navigating the complexities of character encoding in C++ can be daunting, but understanding the differences between UTF and UCS empowers you to make informed decisions regarding string manipulation and data storage. By opting fo
---
Visit these links for original content and any more details, such as alternate solutions, comments, revision history etc. For example, the original title of the Question was: UTF usage in C++ code
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Understanding UTF and UCS in C++: The Ultimate Guide for Unicode Handling
In today's globalized world, it's essential for software applications to support diverse character sets. As a C++ developer, you might encounter scenarios where you need to manipulate strings that contain a variety of characters beyond the typical European alphabets. This leads us to a critical question: What is the difference between UTF and UCS, and how can we effectively represent non-European character sets in C++?
In this guide, we will break down the answers to these questions while providing practical recommendations for internal representation, storage, and wire transport formats.
What are UTF and UCS?
Before diving into implementation strategies, let's clarify the distinction between UTF (Unicode Transformation Format) and UCS (Universal Character Set):
UCS
Fixed Width: UCS encodings use a fixed number of bytes per character. For example, UCS-2 uses 2 bytes for each character.
Limitations: Characters that fall outside the defined range cannot be represented in UCS encodings.
UTF
Variable Width: UTF encodings provide a flexible approach where the number of bytes used can vary. For instance, UTF-16 requires at least 16 bits (or 2 bytes) for a character but may use 4 bytes for characters with more complex code points.
Flexibility: This format allows for a wider range of characters to be encoded.
Recommendations for C++ String Representation
Now that we've established the key differences between UTF and UCS, let's explore practical ways to represent non-European character sets in C++ effectively.
1. Internal Representation Inside the Code
The choice of internal string representation in your C++ application greatly depends on the platform you are using. Here are the common practices:
Windows: Generally, UTF-16 is the preferred internal representation. This format accommodates most characters in the Basic Multilingual Plane (BMP) efficiently, requiring less memory compared to UCS-4.
UNIX: UCS-4 is commonly used. This offers simplicity and allows better manipulation because each character has a consistent size.
Important Considerations:
Memory Usage:
UTF-16 strings use memory effectively for larger texts primarily composed of BMP characters.
UCS-4 simplifies string processing because string characters maintain a consistent representation, eliminating confusion arising from surrogate pairs present in UTF-16.
Interoperability: Some systems may implement UTF-8 internally, which is beneficial for maintaining compatibility with ASCII or ISO-8859 systems since it avoids NULL bytes mid-string, unlike UTF-16 or UCS-4.
2. Best Storage Representation
When it comes to storing your character data, UTF-8 is the recommended encoding. This standard is widely used and efficient for text files:
Advantages of UTF-8:
It compresses characters effectively, especially for texts that consist predominantly of ASCII characters.
It is highly compatible with most modern software systems.
3. Best On-Wire Transport Format
For data transfers between applications, especially across different architectures, UTF-8 also stands out as the optimal transport format due to its flexibility and robustness:
Compatibility: It adheres to the conventions of modern data transmission protocols, mitigating issues with character alignment that can occur with fixed-width formats like UCS.
Efficiency: Reduces the overhead when dealing with non-ASCII data, ensuring smooth interoperability between systems.
Conclusion
Navigating the complexities of character encoding in C++ can be daunting, but understanding the differences between UTF and UCS empowers you to make informed decisions regarding string manipulation and data storage. By opting fo
 0:01:41
0:01:41
 0:03:29
0:03:29
 0:24:52
0:24:52
 0:10:54
0:10:54
 0:09:37
0:09:37
 0:09:43
0:09:43
 0:14:34
0:14:34
 0:01:00
0:01:00
 0:19:07
0:19:07
 0:10:41
0:10:41
 0:24:49
0:24:49
 0:05:41
0:05:41
 0:00:19
0:00:19
 0:07:50
0:07:50
 0:00:11
0:00:11
 1:03:00
1:03:00
 0:17:12
0:17:12
 0:14:36
0:14:36
 0:21:07
0:21:07
 0:00:48
0:00:48
 0:09:11
0:09:11
 0:00:15
0:00:15
 0:07:36
0:07:36
 0:00:23
0:00:23