filmov
tv
What are UTF-8 and UTF-16? Working with Unicode encodings

Показать описание
UTF-8 and UTF-16 are the two most commonly used encoding for Unicode characters. Unicode defines a large character repertoire (1.1 million in theory, of which 145k are defined in Unicode 14.0) which begs the question how to encode all these characters. UTF-8 and UTF-16 are two of the encodings that Unicode defines, and the most popular ones today.
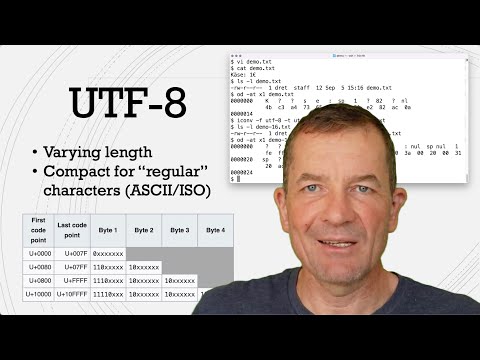
UTF-8 is a variable length encoding that encodes each character in 1-4 bytes, where the standard ASCII repertoire is encoded in 1 byte per character. This encoding makes UTF-8 compact, but it also is a relatively complex encoding.
UTF-16 is less complex and encodes most Unicode characters (and pretty much all in practical use today) in 2 bytes, with some others being encoded in 4 bytes. This means UTF-16 takes up more space for most cases, but it is easier to encode and decode.
Since Unicode is very popular today a lot of tooling has built in support for Unicode and some of its encodings. In addition, there are standalone tools that can be used to investigate files, and to convert them. We demonstrate two such tools with the Unix "od" and "iconv" commands, which allow us to have a close look at a demo file, and to convert it between the two encodings.
Additional Resources:
00:00 Introduction
00:23 UTF-8 and UTF-16 are Text Encodings
00:55 Character Sets
01:26 Unicode as the universal character repertoire
02:27 UTF-8
03:25 UTF-16
04:09 Demo time: Starting with a demo file
04:50 od as a tool for dumping files
05:46 iconv for converting files
07:24 Summary
08:50 Wrap-up
UTF-8 is a variable length encoding that encodes each character in 1-4 bytes, where the standard ASCII repertoire is encoded in 1 byte per character. This encoding makes UTF-8 compact, but it also is a relatively complex encoding.
UTF-16 is less complex and encodes most Unicode characters (and pretty much all in practical use today) in 2 bytes, with some others being encoded in 4 bytes. This means UTF-16 takes up more space for most cases, but it is easier to encode and decode.
Since Unicode is very popular today a lot of tooling has built in support for Unicode and some of its encodings. In addition, there are standalone tools that can be used to investigate files, and to convert them. We demonstrate two such tools with the Unix "od" and "iconv" commands, which allow us to have a close look at a demo file, and to convert it between the two encodings.
Additional Resources:
00:00 Introduction
00:23 UTF-8 and UTF-16 are Text Encodings
00:55 Character Sets
01:26 Unicode as the universal character repertoire
02:27 UTF-8
03:25 UTF-16
04:09 Demo time: Starting with a demo file
04:50 od as a tool for dumping files
05:46 iconv for converting files
07:24 Summary
08:50 Wrap-up
 0:09:37
0:09:37
What are UTF-8 and UTF-16? Working with Unicode encodings
 0:03:29
0:03:29
ASCII, Unicode, UTF-8: Explained Simply
 0:09:37
0:09:37
Characters, Symbols and the Unicode Miracle - Computerphile
 0:01:26
0:01:26
Understanding Unicode, UTF-8, and UTF-16
 0:24:52
0:24:52
Unicode Encoding! UTF-32, UCS-2, UTF-16, & UTF-8!
 0:10:54
0:10:54
Unicode, in friendly terms: ASCII, UTF-8, code points, character encodings, and more
 0:05:46
0:05:46
Oracle SQL Tutorial 26 - UTF-8 and UTF-16
 0:04:01
0:04:01
Oracle SQL Tutorial 30 - UTF-8 and UTF-16 Character Sets
 0:01:50
0:01:50
EXTRA BITS - UTF-8 'nearly' works - Computerphile
 0:10:41
0:10:41
ASCII, Unicode, UTF-32, UTF-8 explained | Examples in Rust, Go, Python
 0:14:20
0:14:20
Characters in a computer - Unicode Tutorial (UTF-32 & UTF-16)(2/3)
 0:01:34
0:01:34
C# : What's the difference between UTF8/UTF16 and Base64 in terms of encoding
 0:05:27
0:05:27
How to Use UTF-8 and UTF-16 Special Characters in Chart JS
 0:19:07
0:19:07
Ep 020: Unicode Code Points and UTF-8 Encoding
 0:14:34
0:14:34
Ep 021: UTF-8 Encoding Examples
 0:03:21
0:03:21
Java :Difference between UTF-8 and UTF-16?(5solution)
 0:09:24
0:09:24
Unicode in UTF-8 umrechnen
 0:10:32
0:10:32
Что такое unicode, ascii, utf-8, utf-16, utf-32 ?
 0:09:11
0:09:11
Unicode vs UTF-8
 0:02:37
0:02:37
The conversion from UTF-16 to UTF-8
 1:03:00
1:03:00
Interesting Characters (UTF-16, utf-8, Unicode, encodings)
 0:05:12
0:05:12
Why I like the UTF-8 Byte Order Mark (BOM)
 0:03:31
0:03:31
Encoding Schemes | ACSII UNICODE ISCII | UTF-8 UTF-16 UTF-32 | Rajnath Prasad
 0:05:41
0:05:41
Unicode 2: Was bedeutet: Unicode, Code Point, Encoding, UTF-8 (Deutsch / German)
Комментарии