filmov
tv
Unicode and Byte Order

Показать описание
In this computer science video you will learn about text files. Specifically, you will see how Unicode code points are encoded into binary and why the byte order, that is the endianness, of some Unicode Transformation Formats could be an important consideration if you’re a programmer handling text data, or if you build websites.
The video demonstrates how Unicode code points are encoded in ASCII, UCS-2, UTF-16, UCS-4, UTF-32 and UTF-8, and it discusses some of the advantages and disadvantages of these encodings. The UTF-16 high surrogate and low surrogate format is explained, including its effect on the available range of code points. The UTF-8 bit patterns are also described in detail.
When saving UTF-16 or UTF-32 text files, it is possible to specify the byte order, which can be either big endian or little endian. The need for a byte order mark (BOM) in a UTF-16 text file is demonstrated by examining it encoding as hexadecimal data. The so called UTF-8 with BOM format is also discussed.
In this computer science video, you will also see why it is important to include a charset meta tag in the head section of a web page, to specify the character encoding. Problems that might occur if, for example, a web page has been encoded with ISO-8859-1 or Windows 1252 are demonstrated.
Chapters:
00:00 Introduction
00:59 Unicode code points
01:45 ASCII
02:24 Universal Character Set UCS-2
03:50 Unicode Transformation Format UTF-16
09:26 Unicode Transformation Format UTF-32
10:48 Unicode Transformation Format UTF-8
14:03 Byte Order
15:07 Byte Order Mark BOM Demonstration
19:47 UTF-8 with BOM Demonstration
20:54 Web page character encoding
24:04 Summary
The video demonstrates how Unicode code points are encoded in ASCII, UCS-2, UTF-16, UCS-4, UTF-32 and UTF-8, and it discusses some of the advantages and disadvantages of these encodings. The UTF-16 high surrogate and low surrogate format is explained, including its effect on the available range of code points. The UTF-8 bit patterns are also described in detail.
When saving UTF-16 or UTF-32 text files, it is possible to specify the byte order, which can be either big endian or little endian. The need for a byte order mark (BOM) in a UTF-16 text file is demonstrated by examining it encoding as hexadecimal data. The so called UTF-8 with BOM format is also discussed.
In this computer science video, you will also see why it is important to include a charset meta tag in the head section of a web page, to specify the character encoding. Problems that might occur if, for example, a web page has been encoded with ISO-8859-1 or Windows 1252 are demonstrated.
Chapters:
00:00 Introduction
00:59 Unicode code points
01:45 ASCII
02:24 Universal Character Set UCS-2
03:50 Unicode Transformation Format UTF-16
09:26 Unicode Transformation Format UTF-32
10:48 Unicode Transformation Format UTF-8
14:03 Byte Order
15:07 Byte Order Mark BOM Demonstration
19:47 UTF-8 with BOM Demonstration
20:54 Web page character encoding
24:04 Summary
 0:24:49
0:24:49
Unicode and Byte Order
 0:05:12
0:05:12
Why I like the UTF-8 Byte Order Mark (BOM)
 0:03:29
0:03:29
ASCII, Unicode, UTF-8: Explained Simply
 0:17:18
0:17:18
Code Pages, Character Encoding, Unicode, UTF-8 and the BOM - Computer Stuff They Didn't Teach Y...
 0:11:04
0:11:04
what is a BOM (byte-order-marker) (intermediate) anthony explains #560
 0:10:54
0:10:54
Unicode, in friendly terms: ASCII, UTF-8, code points, character encodings, and more
 0:04:47
0:04:47
4 Big Endian vs Little Endian Byte Ordering
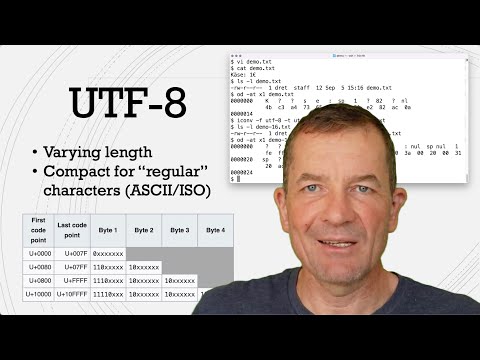 0:09:37
0:09:37
What are UTF-8 and UTF-16? Working with Unicode encodings
 0:13:16
0:13:16
Byte Order (Endianness)
 0:09:37
0:09:37
Characters, Symbols and the Unicode Miracle - Computerphile
 0:30:06
0:30:06
A Brief History of Unicode
 0:54:14
0:54:14
Character Encoding - 🅷🅰🅽🅳🆂 🅾🅽 🅲🆁🅰🆂🅷 🅲🅾🆄🆁🆂🅴
 0:09:07
0:09:07
Data Conversions and Byte-Order-Marks
 0:14:36
0:14:36
Understanding text for C Programmers (UTF-8, Unicode, ASCII)
 0:19:07
0:19:07
Ep 020: Unicode Code Points and UTF-8 Encoding
 0:02:55
0:02:55
Apple: TextEdit removes Byte-Order-Mark (BOM) from Unicode/UTF files. How to fix? (3 Solutions!!)
 0:09:36
0:09:36
Bytes and encodings in Python
 0:00:05
0:00:05
! | Unicode Lore
 0:40:36
0:40:36
U is for Unicode: Solving the Mystery
 0:12:49
0:12:49
ASCII and Unicode Character Sets
 0:44:25
0:44:25
Talk: James Bennett - A 🐍's guide to Unicode
 0:10:41
0:10:41
ASCII, Unicode, UTF-32, UTF-8 explained | Examples in Rust, Go, Python
 0:09:11
0:09:11
Unicode vs UTF-8
 0:01:16
0:01:16
C# : There is no Unicode byte order mark. Cannot switch to Unicode
Комментарии