filmov
tv
Linear Least Squares to Solve Nonlinear Problems

Показать описание
Ever wondered how Excel comes up with those neat trendlines? Here's the the theory so you can model your data however you like! #SoME1
 0:15:32
0:15:32
Least squares approximation | Linear Algebra | Khan Academy
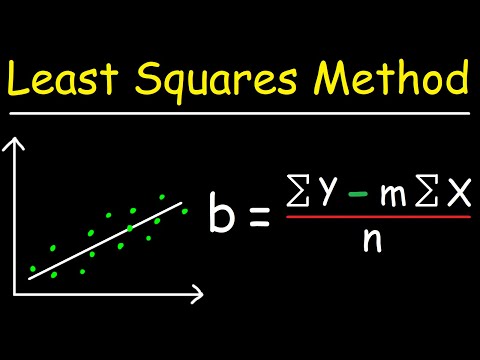 0:15:05
0:15:05
Linear Regression Using Least Squares Method - Line of Best Fit Equation
 0:18:27
0:18:27
Linear Algebra 6.5.1 Least Squares Problems
 0:12:27
0:12:27
Linear Least Squares to Solve Nonlinear Problems
 0:10:15
0:10:15
Least squares using matrices | Lecture 26 | Matrix Algebra for Engineers
 0:06:28
0:06:28
Determine a Least Squares Solutions to Ax=b
 0:07:52
0:07:52
Least Squares Approximation
 0:49:51
0:49:51
9. Four Ways to Solve Least Squares Problems
 0:11:53
0:11:53
Linear Systems of Equations, Least Squares Regression, Pseudoinverse
 0:10:31
0:10:31
The Least Squares Formula: A Derivation
 0:12:27
0:12:27
Linear Least Squares
 0:18:50
0:18:50
Least squares examples | Alternate coordinate systems (bases) | Linear Algebra | Khan Academy
 0:08:04
0:08:04
Least Squares Approximation
 0:12:13
0:12:13
Deriving the least squares estimators of the slope and intercept (simple linear regression)
 0:16:56
0:16:56
Linear Regression Least Squares Method
 0:06:38
0:06:38
Linear Least Squares Estimation
 0:03:48
0:03:48
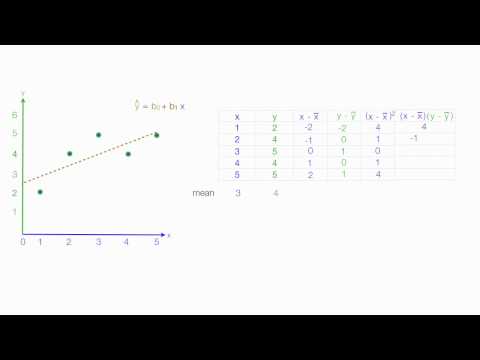
Calculating the Least Squares Regression Line by Hand
 0:08:29
0:08:29
How to calculate linear regression using least square method
 0:29:45
0:29:45
Harvard AM205 video 1.6 - Linear least squares
 0:07:28
0:07:28
Least Squares Approximations
 0:03:33
0:03:33
11.3.6 Solving the Linear Least-squares Problem Via QR Factorization
 0:28:25
0:28:25
Least Square Solution of a Given System of Linear equations
 0:09:30
0:09:30
Example 1: Finding a least squares solution of an inconsistent system
 0:10:56
0:10:56
Nonlinear Least Squares
Комментарии