filmov
tv
Efficient Large-Scale Language Model Training on GPU Clusters
Показать описание
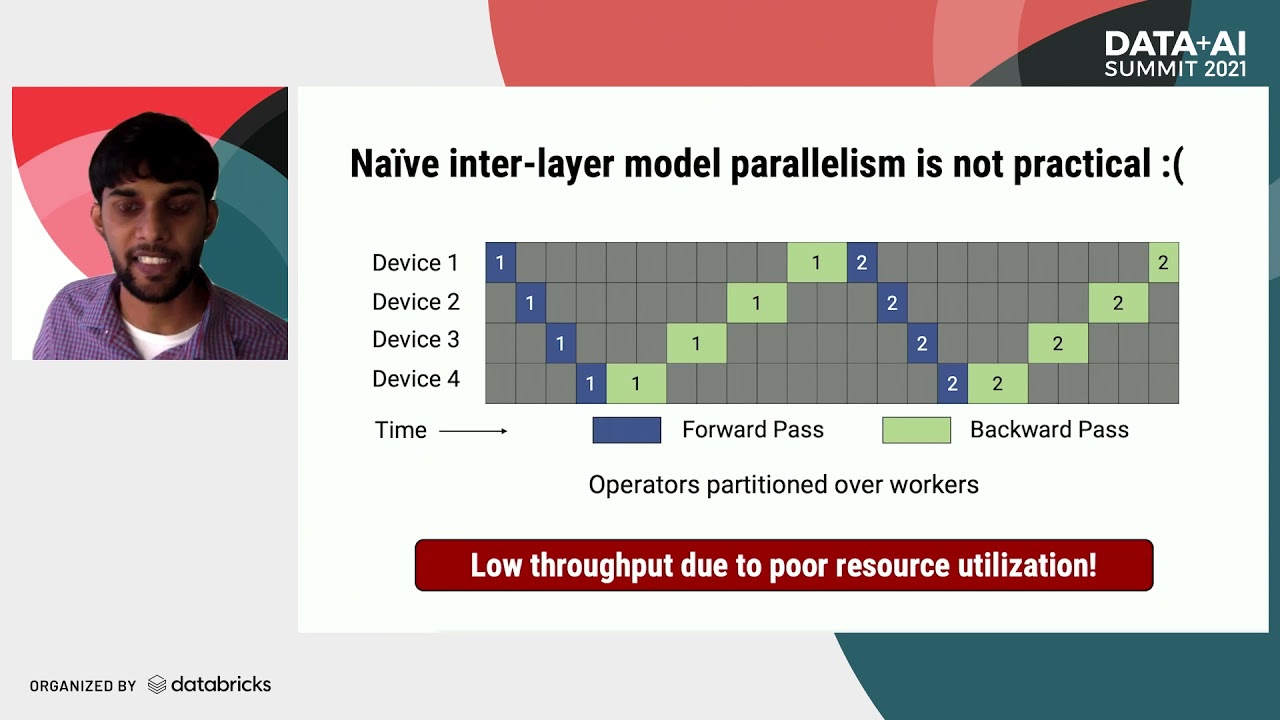
Large language models have led to state-of-the-art accuracies across a range of tasks. However, training these large models efficiently is challenging for two reasons: a) GPU memory capacity is limited, making it impossible to fit large models on a single GPU or even on a multi-GPU server; and b) the number of compute operations required to train these models can result in unrealistically long training times. New methods of model parallelism such as tensor and pipeline parallelism have been proposed to address these challenges; unfortunately, naive usage leads to fundamental scaling issues at thousands of GPUs due to various reasons, e.g., expensive cross-node communication or idle periods waiting on other devices.
Connect with us:
Connect with us:
 0:22:58
0:22:58
Efficient Large-Scale Language Model Training on GPU Clusters
 0:24:04
0:24:04
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM | Jared Casper
 0:07:41
0:07:41
Efficient Large Scale Language Modeling with Mixtures of Experts
 0:55:59
0:55:59
Training LLMs at Scale - Deepak Narayanan | Stanford MLSys #83
 0:37:36
0:37:36
RAS: Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM - G. Perrotta
 1:22:58
1:22:58
Ultimate Guide To Scaling ML Models - Megatron-LM | ZeRO | DeepSpeed | Mixed Precision
 0:08:37
0:08:37
Efficient Large Language Model training with LoRA and Hugging Face PEFT
 2:15:57
2:15:57
Efficient Large-Scale AI Workshop | Session 2: Training and inference efficiency
 0:47:25
0:47:25
AWS re:Invent 2024 - Scaling generative AI models for millions of users in Roblox (GAM310)
 0:34:52
0:34:52
Sebastian Borgeaud - Efficient Training of Large Language Models @ UCL DARK
 0:04:20
0:04:20
How are LLMs Trained? Distributed Training in AI (at NVIDIA)
 0:58:32
0:58:32
Exploiting Parallelism in Large Scale DL Model Training: From Chips to Systems to Algorithms
 2:12:42
2:12:42
Efficient Large-Scale AI Workshop | Session 1: Skills acquisition and new capabilities
 0:35:45
0:35:45
How to Build an LLM from Scratch | An Overview
 2:06:35
2:06:35
Efficient Large-Scale AI Workshop | Session 3: Aligning models with human intent
 0:00:48
0:00:48
Efficient Fine-Tuning for Llama 3 Language Models
 0:10:52
0:10:52
Megatron-LM: Mastering Multi-Billion Parameter Language Models
 0:21:07
0:21:07
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs | Haibin Lin
 0:24:07
0:24:07
AI can't cross this line and we don't know why.
 0:18:29
0:18:29
Scaling AI Model Training and Inferencing Efficiently with PyTorch
 0:31:00
0:31:00
Miguel Martínez & Meriem Bendris - Building Large-scale Localized Language Models
 0:06:28
0:06:28
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
 0:00:48
0:00:48
Unlocking Efficient Training for LLMs: The Power of Productivity per Watt - Elon Musk
 0:49:58
0:49:58
Exploiting Parallelism in Large Scale Deep Learning Model Training: Chips to Systems to Algorithms
Комментарии