filmov
tv
Linux Login Workflow | Standard Input, Output, and Error Explained | Linux File Descriptors

Показать описание
Welcome to pathforit, your ultimate learning destination for mastering Linux, Cloud Computing, AWS, and more. In this session, led by your expert instructor Durga Prasad Yadav, we focus on a very essential part of Linux operations: the login workflow and the powerful concepts of Standard Input, Standard Output, and Standard Error.
These concepts form the core of how users interact with Linux systems and how Linux processes information internally. Whether you're a beginner or an intermediate learner aiming for mastery, this session gives you deep insights into how Linux handles user sessions and manages data flow within the system.
🎯 Key Concepts Covered in This Video
In this video, you'll gain a crystal-clear understanding of:
✅ How a Linux user login process works from start to finish
✅ The hidden journey your credentials take during authentication
✅ What happens in the background when your session starts
✅ The roles of system components like user databases, environment files, and shells
✅ How Linux receives inputs from users or devices
✅ How Linux sends normal messages (output) to users
✅ How Linux handles error messages separately from successful messages
✅ The meaning of file descriptors: 0, 1, and 2
✅ How Linux separates different kinds of information
✅ Why this separation is crucial for developers, system admins, and DevOps professionals
This is not just a tutorial — it’s your deep-dive into the inner workings of Linux as a true multitasking operating system.
🔐 Part 1: The Linux Login Workflow – Behind the Scenes
When a user attempts to log into a Linux system, a well-defined and secure process is triggered in the background. It involves several system files, authentication mechanisms, and environmental setups. Here's what happens under the hood:
🧩 Step 1: Displaying the Login Interface
Linux systems may display a graphical login screen (GUI) or a textual interface (terminal-based), depending on the configuration. This interface is responsible for collecting your credentials like username and password.
🧩 Step 2: Username Verification
Once a username is entered, Linux refers to an internal file that stores details about all registered users on the system. It checks if the username exists and what associated properties are stored, such as the user’s home directory and default shell.
🧩 Step 3: Password Authentication
Passwords in Linux are not stored in plain text. Instead, they are encrypted and kept in a secure location. The system uses a special authentication framework called PAM (Pluggable Authentication Modules). PAM is responsible for verifying your password and allowing or denying access based on its validity.
🧩 Step 4: Initializing the Shell
Upon successful authentication, the system sets up your session by launching the shell — the command-line interface where users enter instructions. The system determines which shell to use based on settings in your user profile.
🧩 Step 5: Reading Configuration Files
To personalize your environment, Linux reads certain configuration files. These files contain instructions to set up variables, aliases, prompts, and more, shaping how your session looks and behaves.
🧩 Step 6: Session Starts
Once all initialization is complete, you're provided with a ready-to-use interactive session. Now you're free to begin interacting with the system — running applications, accessing files, or managing system tasks.
🧠 Why Understanding the Login Workflow Matters
The login workflow is foundational to everything else you do in Linux. Here’s why it’s important:
🛡️ Security – Proper authentication keeps unauthorized users out
⚙️ Customization – Configuration files allow tailored user environments
📈 Performance – Understanding processes helps in resource management
🧩 Troubleshooting – If something goes wrong, knowing each step helps isolate the issue
🧠 Foundational Knowledge – Most advanced concepts build upon this process
🧾 Part 2: Standard Input, Output, and Error – The Core of Linux Communication
Linux follows a stream-based design, where it deals with three primary types of data streams. These streams manage how data enters and exits programs. Every program, script, or command uses these data channels to communicate with users and other processes.
💡 Real-Life Applications of These Concepts
Understanding these concepts allows you to work smartly and safely in Linux. Here’s how:
📁 1. Input Automation
System admins often use files or devices as input sources to automate repetitive tasks like database imports, system maintenance, or backups.
🧾 2. Output Reporting
Programs that generate reports or summaries send data through standard output. This can be redirected to a screen, file, or even another application for further processing.
⚠️ 3. Error Monitoring
Errors are sent to standard error. This separation allows for automated monitoring tools to scan for failures and alert administrators instantly, without mixing these messages with regular data.
These concepts form the core of how users interact with Linux systems and how Linux processes information internally. Whether you're a beginner or an intermediate learner aiming for mastery, this session gives you deep insights into how Linux handles user sessions and manages data flow within the system.
🎯 Key Concepts Covered in This Video
In this video, you'll gain a crystal-clear understanding of:
✅ How a Linux user login process works from start to finish
✅ The hidden journey your credentials take during authentication
✅ What happens in the background when your session starts
✅ The roles of system components like user databases, environment files, and shells
✅ How Linux receives inputs from users or devices
✅ How Linux sends normal messages (output) to users
✅ How Linux handles error messages separately from successful messages
✅ The meaning of file descriptors: 0, 1, and 2
✅ How Linux separates different kinds of information
✅ Why this separation is crucial for developers, system admins, and DevOps professionals
This is not just a tutorial — it’s your deep-dive into the inner workings of Linux as a true multitasking operating system.
🔐 Part 1: The Linux Login Workflow – Behind the Scenes
When a user attempts to log into a Linux system, a well-defined and secure process is triggered in the background. It involves several system files, authentication mechanisms, and environmental setups. Here's what happens under the hood:
🧩 Step 1: Displaying the Login Interface
Linux systems may display a graphical login screen (GUI) or a textual interface (terminal-based), depending on the configuration. This interface is responsible for collecting your credentials like username and password.
🧩 Step 2: Username Verification
Once a username is entered, Linux refers to an internal file that stores details about all registered users on the system. It checks if the username exists and what associated properties are stored, such as the user’s home directory and default shell.
🧩 Step 3: Password Authentication
Passwords in Linux are not stored in plain text. Instead, they are encrypted and kept in a secure location. The system uses a special authentication framework called PAM (Pluggable Authentication Modules). PAM is responsible for verifying your password and allowing or denying access based on its validity.
🧩 Step 4: Initializing the Shell
Upon successful authentication, the system sets up your session by launching the shell — the command-line interface where users enter instructions. The system determines which shell to use based on settings in your user profile.
🧩 Step 5: Reading Configuration Files
To personalize your environment, Linux reads certain configuration files. These files contain instructions to set up variables, aliases, prompts, and more, shaping how your session looks and behaves.
🧩 Step 6: Session Starts
Once all initialization is complete, you're provided with a ready-to-use interactive session. Now you're free to begin interacting with the system — running applications, accessing files, or managing system tasks.
🧠 Why Understanding the Login Workflow Matters
The login workflow is foundational to everything else you do in Linux. Here’s why it’s important:
🛡️ Security – Proper authentication keeps unauthorized users out
⚙️ Customization – Configuration files allow tailored user environments
📈 Performance – Understanding processes helps in resource management
🧩 Troubleshooting – If something goes wrong, knowing each step helps isolate the issue
🧠 Foundational Knowledge – Most advanced concepts build upon this process
🧾 Part 2: Standard Input, Output, and Error – The Core of Linux Communication
Linux follows a stream-based design, where it deals with three primary types of data streams. These streams manage how data enters and exits programs. Every program, script, or command uses these data channels to communicate with users and other processes.
💡 Real-Life Applications of These Concepts
Understanding these concepts allows you to work smartly and safely in Linux. Here’s how:
📁 1. Input Automation
System admins often use files or devices as input sources to automate repetitive tasks like database imports, system maintenance, or backups.
🧾 2. Output Reporting
Programs that generate reports or summaries send data through standard output. This can be redirected to a screen, file, or even another application for further processing.
⚠️ 3. Error Monitoring
Errors are sent to standard error. This separation allows for automated monitoring tools to scan for failures and alert administrators instantly, without mixing these messages with regular data.
 0:40:52
0:40:52
Linux Login Workflow | Standard Input, Output, and Error Explained | Linux File Descriptors
 0:04:54
0:04:54
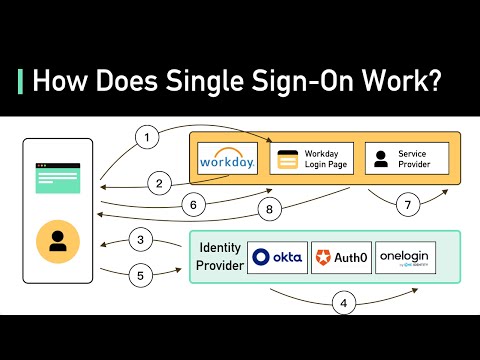
What Is Single Sign-on (SSO)? How It Works
 0:02:49
0:02:49
SAML vs. OpenID (OIDC): What's the Difference?
 0:04:32
0:04:32
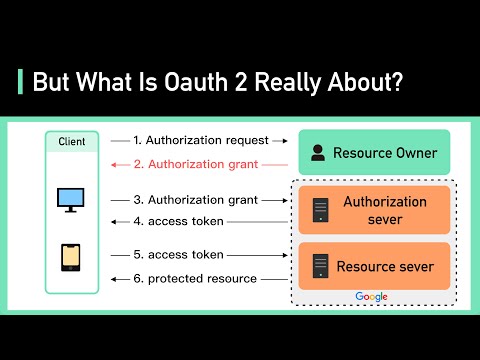
OAuth 2 Explained In Simple Terms
 0:02:53
0:02:53
Linux Directories Explained in 100 Seconds
 0:09:28
0:09:28
My FAVORITE Minimal Login Manager for Linux!
 0:00:56
0:00:56
LOGIN like a NERD on Arch Linux. CUSTOMIZE the standard Arch Linux Login. #shorts
 0:02:33
0:02:33
Bash in 100 Seconds
 0:06:00
0:06:00
Linux Command: 'tee' - Watch & Log Command Output
 0:14:19
0:14:19
What is LDAP and Active Directory ? How LDAP works and what is the structure of LDAP/AD?
 0:10:50
0:10:50
60 Linux Commands you NEED to know (in 10 minutes)
![[024] MVS 3.8:](https://i.ytimg.com/vi/GV-dWA5Flec/hqdefault.jpg) 1:03:26
1:03:26
[024] MVS 3.8: A C Programming Workflow
 0:07:23
0:07:23
What is single sign on (sso) | How sso works with saml | SAML authentication with AD (2023)
 0:05:07
0:05:07
'Basic Authentication' in Five Minutes
 0:38:32
0:38:32
Optimizing Your Workflow with Modern Linux Commands
 0:00:43
0:00:43
The greatest programming language of all time
 0:00:58
0:00:58
Master Linux Input Redirection Like a Pro
 0:22:23
0:22:23
IAR Systems: Tips &Tricks to Boost Performance in Modern Development Workflows | ESTC Summit
 0:44:16
0:44:16
10 Linux Terminal Tips and Tricks to Enhance Your Workflow
 0:00:28
0:00:28
How to Linux: Package Management #shorts
 0:00:55
0:00:55
Как запускать Windows-программы на Linux 🐧?
 0:00:40
0:00:40
Stop looking for new notetaking apps. This is all you need.
 0:11:24
0:11:24
Edu 0014 : workflow series - Adding herbstluftwm to our computer system - not in any script
 0:00:15
0:00:15
What people think when you say 'Linux' #linuxmyths #kde #plasma #lin...
Комментарии