filmov
tv
Best Practices Working with Billion-row Tables in Databases

Показать описание
Chapters
Intro 0:00
1. Brute Force Distributed Processing 2:30
2. Working with a Subset of table 3:35
2.1 Indexing 3:55
2.2 Partitioning 5:30
2.3 Sharding 7:30
3. Avoid it all together (reshuffle the whole design) 9:10
Summary 11:30
🎙️Listen to the Backend Engineering Podcast
🏭 Backend Engineering Videos
💾 Database Engineering Videos
🏰 Load Balancing and Proxies Videos
🏛️ Software Archtiecture Videos
📩 Messaging Systems
Become a Member
Support me on PayPal
Stay Awesome,
Hussein
 0:13:41
0:13:41
Best Practices Working with Billion-row Tables in Databases
 0:09:07
0:09:07
Querying 100 Billion Rows using SQL, 7 TB in a single table
 0:04:08
0:04:08
SQL indexing best practices | How to make your database FASTER!
 0:08:12
0:08:12
5 Secrets for making PostgreSQL run BLAZING FAST. How to improve database performance.
 0:05:50
0:05:50
From 2.5 million row reads to 1 (optimizing my database performance)
 0:05:57
0:05:57
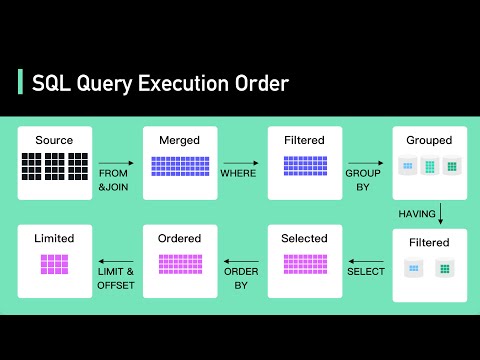
Secret To Optimizing SQL Queries - Understand The SQL Execution Order
 0:07:01
0:07:01
Update a Table with Millions of Rows in SQL (Fast)
 0:00:57
0:00:57
SQL Server 2019 querying 1 trillion rows in 100 seconds
 0:02:26
0:02:26
Optimizing MySQL Very Fast Loading Billion rows from Client to Server
 0:43:39
0:43:39
Processing 1 Billion Rows Per Second
 0:05:01
0:05:01
Try limiting rows when creating reporting for big data in Power BI
 0:03:18
0:03:18
SQL Query Optimization - Tips for More Efficient Queries
 0:10:57
0:10:57
10 Million Rows of data Analyzed using Excel's Data Model
 0:00:19
0:00:19
STOP doing your SQUATS like this!
 0:04:43
0:04:43
Very slow query performance in aws postgresql for a table with 4 billion rows
 0:12:23
0:12:23
Best Practices in Designing Tables
 0:24:44
0:24:44
Superpowering Tableau for Trillions of Rows
 0:06:44
0:06:44
how to load one billion rows into an sql database
 0:00:37
0:00:37
CIA Spy EXPLAINS Mossad’s Ruthless Tactics 🫣 | #shorts
 0:00:27
0:00:27
The Strongest Muscle In Your Body 🤨 (not what you think)
 0:00:24
0:00:24
How Much Does 13,000,000 YouTube Views Pay You? #shorts
 0:26:03
0:26:03
5 million + random rows in less than 100 seconds using SQL
 0:03:21
0:03:21
Snowflake Data Cloud 288 Billion Rows (10TB) -APOS Live Data Gateway Performance with Large DataSets
 0:00:16
0:00:16
HOW TO DO A 1 ARM PUSHUP?
Комментарии