filmov
tv
Neural Network Training (Part 3): Gradient Calculation
Показать описание
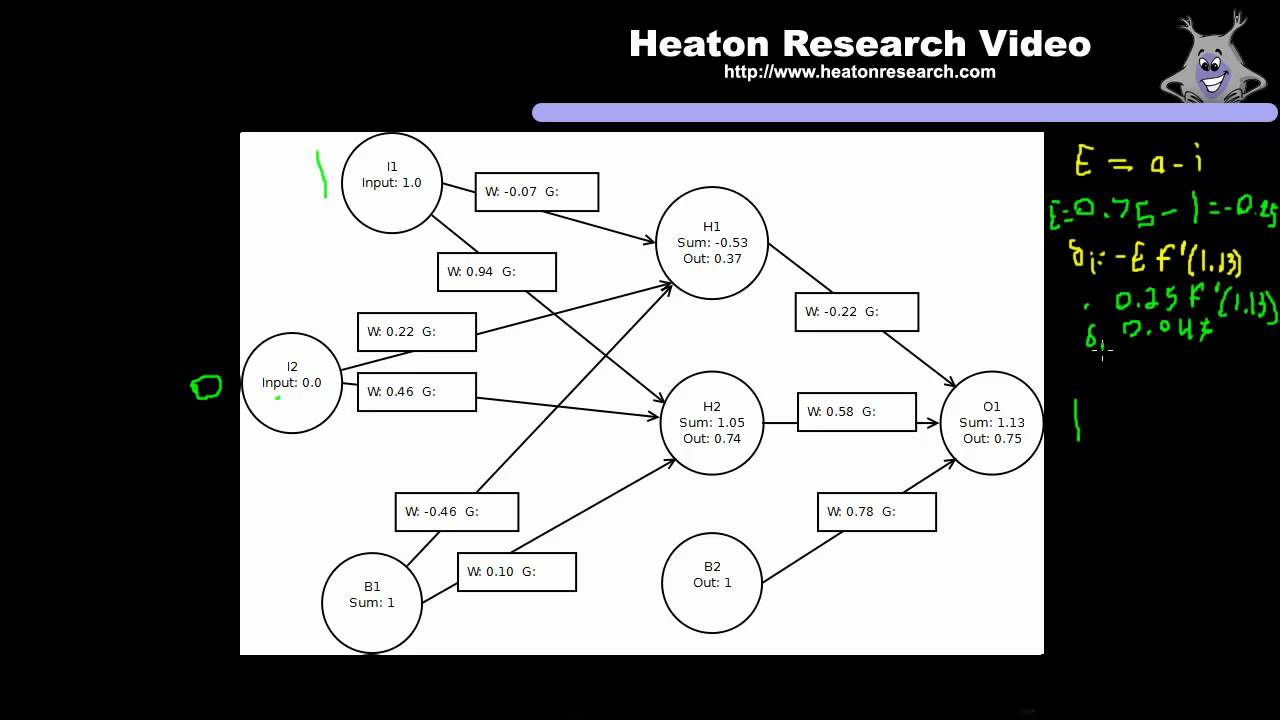
In this video we will see how to calculate the gradients of a neural network. The gradients are the individual error for each of the weights in the neural network. In the next video we will see how these gradients can be used to modify the weights of the neural network.
 0:15:53
0:15:53
Neural Network Training (Part 3): Gradient Calculation
 0:20:21
0:20:21
10.16: Neural Networks: Backpropagation Part 3 - The Nature of Code
 0:07:24
0:07:24
Part 3: Training the Neural Network
 0:55:11
0:55:11
Introduction to Neural Networks - Part 3: Convolution Neural Networks (Cyrill Stachniss, 2021)
 0:14:30
0:14:30
Better training of our neural network - Let's code a neural network in plain JavaScript Part 3
 0:12:45
0:12:45
Coding a Neural Network: A Beginner's Guide (part 3)
 0:54:40
0:54:40
Introduction to Deep Learning - 8. Training Neural Networks Part 3 (Summer 2020)
 0:19:16
0:19:16
Neural Network from scratch - Part 3 (Backward Propagation)
 1:06:21
1:06:21
EfficientML.ai Lecture 7 - Neural Architecture Search Part I (MIT 6.5940, Fall 2024)
 0:09:51
0:09:51
Neural Network Fundamentals (Part3): Regression
 0:11:19
0:11:19
How To Code A Neural Network From Scratch Part 3 - Activating a neuron
 0:25:33
0:25:33
Understanding Convolutional Neural Networks | Part 3 / 3 - Transfer Learning and Explainable AI
 1:09:24
1:09:24
ADAMS - L3 - Neural Network Training - Part 3
 0:22:35
0:22:35
'How neural networks learn' - Part III: Generalization and Overfitting
 0:16:19
0:16:19
Equivariant Neural Networks | Part 3/3 - Transformers and GNNs
 0:12:47
0:12:47
What is backpropagation really doing? | Chapter 3, Deep learning
 0:05:15
0:05:15
Neural Structured Learning - Part 3: Training with synthesized graphs
 0:15:02
0:15:02
Neural Network Calculation (Part 3): Feedforward Neural Network Calculation
 1:55:58
1:55:58
Building makemore Part 3: Activations & Gradients, BatchNorm
 1:09:36
1:09:36
CS231n Winter 2016: Lecture 6: Neural Networks Part 3 / Intro to ConvNets
 2:06:30
2:06:30
NEURAL NETWORKS, PART 3! - CS50 Live, EP. 58
 0:05:33
0:05:33
Introducing convolutional neural networks (ML Zero to Hero - Part 3)
 0:06:56
0:06:56
Neural Networks Demystified [Part 3: Gradient Descent]
 1:27:35
1:27:35
Lecture 5: Neural Networks: Learning the network: Part 3
Комментарии