filmov
tv
26 - Prior and posterior predictive distributions - an introduction

Показать описание
This video provides an introduction to the
 0:05:44
0:05:44
26 - Prior and posterior predictive distributions - an introduction
 0:02:20
0:02:20
Prior And Posterior - Intro to Statistics
 0:11:51
0:11:51
Prior and Posterior Probabilities in Bayesian Networks
 0:01:01
0:01:01
Assisted Lithology Interpretation – Prior & Posterior Probability
 0:00:27
0:00:27
Prior And Posterior Solution - Intro to Statistics
 0:38:19
0:38:19
Bayesian Statistics: An Introduction
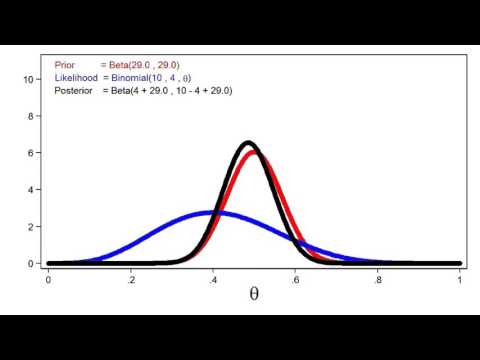 0:09:12
0:09:12
Introduction to Bayesian statistics, part 1: The basic concepts
 0:06:41
0:06:41
Bayesian statistics - Summarizing a posterior distribution
 0:07:23
0:07:23
Bayesian posterior sampling
 0:09:41
0:09:41
An example of how an improper prior leads to an improper posterior
 0:11:16
0:11:16
What is a posterior predictive check and why is it useful?
 0:03:28
0:03:28
Bayesian posterior probabilities for one-sided alternative hypotheses
 0:28:36
0:28:36
Prior and Posterior Distributions
 0:12:26
0:12:26
Estimating the posterior predictive distribution by sampling
 0:07:23
0:07:23
Bayesian posterior sampling
 0:30:31
0:30:31
Posterior & MAP for Normal distribution with unknown precision
 0:44:48
0:44:48
Bayesian fundamentals (Likelihood, Prior, Posterior) in R
 0:08:37
0:08:37
Lecture 10a - Prior and Posterior Probability
 0:13:14
0:13:14
3. Bayesian Posterior Distributions & Conjugate Priors
 0:09:51
0:09:51
[Bayesian inference for a mean] Prior and posterior for mean and standard deviation part 1
 0:29:42
0:29:42
[Bayesian inference for a mean] Prior and posterior for mean and standard deviation part 3
 0:04:00
0:04:00
Decision Analysis 5: Posterior (Revised) Probability Calculations
 0:02:15
0:02:15
Posterior Density - Introduction
 0:04:52
0:04:52
Prior and Posterior Distribution (Poisson & Exponential Distribution)
Комментарии