filmov
tv
Managing Spark Partitions | Spark Tutorial | Spark Interview Question

Показать описание
#Apache #BigData #Spark #Partitions #Shuffle #Stage #Internals #Performance #optimisation #DeepDive #Join #Shuffle:
Please join as a member in my channel to get additional benefits like materials in BigData , Data Science, live streaming for Members and many more
About us:
We are a technology consulting and training providers, specializes in the technology areas like : Machine Learning,AI,Spark,Big Data,Nosql, graph DB,Cassandra and Hadoop ecosystem.
Visit us :
Twitter :
Thanks for watching
Please Subscribe!!! Like, share and comment!
Please join as a member in my channel to get additional benefits like materials in BigData , Data Science, live streaming for Members and many more
About us:
We are a technology consulting and training providers, specializes in the technology areas like : Machine Learning,AI,Spark,Big Data,Nosql, graph DB,Cassandra and Hadoop ecosystem.
Visit us :
Twitter :
Thanks for watching
Please Subscribe!!! Like, share and comment!
 0:05:12
0:05:12
Spark Basics | Partitions
 0:11:20
0:11:20
Managing Spark Partitions | Spark Tutorial | Spark Interview Question
 0:14:33
0:14:33
Apache Spark : Managing Spark Partitions with Coalesce and Repartition
 0:08:32
0:08:32
Spark Executor Core & Memory Explained
 0:03:43
0:03:43
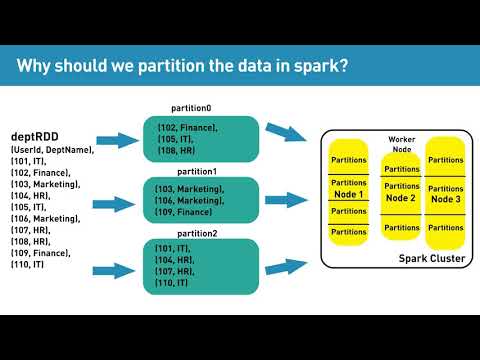
Why should we partition the data in spark?
 0:08:37
0:08:37
Trending Big Data Interview Question - Number of Partitions in your Spark Dataframe
 1:30:18
1:30:18
Apache Spark Core—Deep Dive—Proper Optimization Daniel Tomes Databricks
 0:12:43
0:12:43
How Spark Creates Partitions || Spark Parallel Processing || Spark Interview Questions and Answers
 1:42:12
1:42:12
Modernising data analytics with Databricks
 0:09:15
0:09:15
Spark Join and shuffle | Understanding the Internals of Spark Join | How Spark Shuffle works
 0:05:21
0:05:21
Basics of Apache Spark | Shuffle Partition [200] | learntospark
 0:19:03
0:19:03
Shuffle Partition Spark Optimization: 10x Faster!
 0:12:27
0:12:27
All about partitions in spark
 0:06:50
0:06:50
Spark [Executor & Driver] Memory Calculation
 0:01:17
0:01:17
Demo: Spark 3 Dynamic Partition Pruning
 0:09:15
0:09:15
Partition vs bucketing | Spark and Hive Interview Question
 0:29:29
0:29:29
Lessons From the Field: Applying Best Practices to Your Apache Spark Applications - Silvio Fiorito
 0:08:25
0:08:25
Apache Spark Partitions Introduction
 0:01:19
0:01:19
How Does Spark Partition the Data | Hadoop Interview Questions and Answers | Spark Partitioning
 0:03:47
0:03:47
Determining the number of partitions
 0:07:38
0:07:38
Spark Out of Memory Issue | Spark Memory Tuning | Spark Memory Management | Part 1
 0:20:20
0:20:20
Spark performance optimization Part1 | How to do performance optimization in spark
 0:00:59
0:00:59
Partitions and CPU Core Allocation in Apache Spark
 0:13:45
0:13:45
Spark Application | Partition By in Spark | Chapter - 2 | LearntoSpark
Комментарии