filmov
tv
Partition vs bucketing | Spark and Hive Interview Question

Показать описание
This video is part of the Spark learning Series. Spark provides different methods to optimize the performance of queries. So As part of this video, we are covering the following
What is Partitioning
How does partitioning help to improve performance
What is Bucketing
How does bucketing helps to improve performance
Difference between Partitioning and Bucketing
How Spark's performance is impacted by Dynamic Partition Pruning
Here are a few Links useful for you
Spark performance tuning:
If you are interested to join our community. Please join the following groups
You can drop me an email for any queries at
#apachespark #sparktutorial #bigdata
#spark #hadoop #spark3
What is Partitioning
How does partitioning help to improve performance
What is Bucketing
How does bucketing helps to improve performance
Difference between Partitioning and Bucketing
How Spark's performance is impacted by Dynamic Partition Pruning
Here are a few Links useful for you
Spark performance tuning:
If you are interested to join our community. Please join the following groups
You can drop me an email for any queries at
#apachespark #sparktutorial #bigdata
#spark #hadoop #spark3
 0:09:15
0:09:15
Partition vs bucketing | Spark and Hive Interview Question
 0:08:53
0:08:53
Partition vs Bucketing | Data Engineer interview
 0:13:16
0:13:16
Partitioning vs Bucketing By Example | Spark | big data interview questions #13 | TeKnowledGeek
 0:07:52
0:07:52
6.6 Hive and Spark | Partitions vs Bucketing | Spark Interview Questions
 0:27:52
0:27:52
Partitioning and bucketing in Spark | Lec-9 | Practical video
 0:05:12
0:05:12
Spark Basics | Partitions
 0:22:03
0:22:03
75. Databricks | Pyspark | Performance Optimization - Bucketing
 0:10:41
0:10:41
Partitioning vs Bucketing in Hive | Hive Interview questions and answers | Session 1 - Trendytech
 0:12:54
0:12:54
Partitioning vs Bucketing | Interview Question | PySpark #pyspark #bigdata #pwc #interview
 0:35:04
0:35:04
Bucketing - The One Spark Optimization You're Not Doing
 0:07:13
0:07:13
Hive Partition with Bucket Explained
 0:53:51
0:53:51
Master Spark Partitioning and Bucketing: Top Interview Questions Answered
 0:18:34
0:18:34
Hive Partition [ Static Vs Dynamic]
 0:13:06
0:13:06
Hive Partition And Bucketing Example - Bigdata Hive Tutorial Hive Bucketing And Partitioning
 0:08:00
0:08:00
Mastering Hive Tutorial | Partition vs Bucket | | Interview Question
 0:19:55
0:19:55
Hive Bucket End to End Explained
 0:03:43
0:03:43
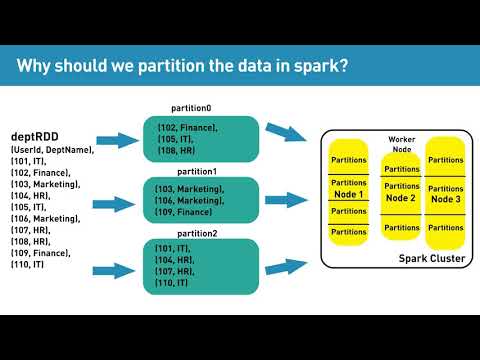
Why should we partition the data in spark?
 0:12:24
0:12:24
Ch.02-34 Partitioning vs Bucketing | Data Modeling
 0:12:06
0:12:06
Spark Interview Question | Bucketing | Spark SQL
 0:03:08
0:03:08
Difference Between Partition and Bucketing in Hive
 0:13:09
0:13:09
45. Databricks | Spark | Pyspark | PartitionBy
 0:08:38
0:08:38
6.7 Decide Number Of Buckets in Hive and spark | Partition and Bucketing
 0:29:17
0:29:17
Bucketing in Spark SQL 2 3 with Jacek Laskowski
![Spark [Hash Partition]](https://i.ytimg.com/vi/KbaLrFgGbNw/hqdefault.jpg) 0:17:37
0:17:37
Spark [Hash Partition] Explained
Комментарии