filmov
tv
Spark Application | Partition By in Spark | Chapter - 2 | LearntoSpark

Показать описание
In this video, we will learn about the partitionBy in Spark Dataframe Writer. We will have a demo on how to save the data by creating a partition on date column using PySpark.
Blog link to learn more on Spark:
Linkedin profile:
FB page:
Github:
Blog link to learn more on Spark:
Linkedin profile:
FB page:
Github:
 0:03:43
0:03:43
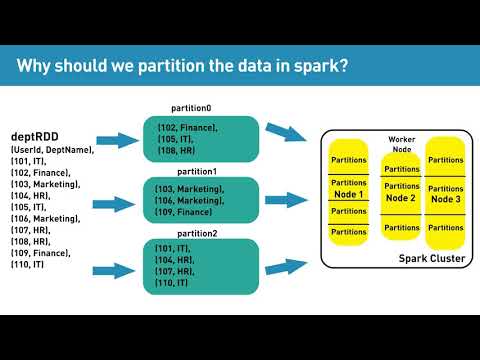
Why should we partition the data in spark?
 0:13:45
0:13:45
Spark Application | Partition By in Spark | Chapter - 2 | LearntoSpark
 0:04:52
0:04:52
How To Set And Get Number Of Partition In Spark | Spark Partition | Big Data
 0:05:09
0:05:09
Partition the Data using Apache Spark with Java
 0:19:03
0:19:03
Shuffle Partition Spark Optimization: 10x Faster!
 0:04:47
0:04:47
Partition the Data using Apache Spark with Scala
 0:01:19
0:01:19
How Does Spark Partition the Data | Hadoop Interview Questions and Answers | Spark Partitioning
 0:20:22
0:20:22
Sparkling: Speculative Partition of Data for Spark Applications - Peilong Li
 1:15:48
1:15:48
Devday | Apache Spark Under The Hood
 0:08:32
0:08:32
Spark Executor Core & Memory Explained
 0:10:11
0:10:11
How to use Windowing Functions in Apache Spark | Window Functions | OVER | PARTITION BY | ORDER BY
 0:09:15
0:09:15
Partition vs bucketing | Spark and Hive Interview Question
 0:09:04
0:09:04
Understanding and Working with Spark Web UI | Local Check Point | Scheduler | Max Partition Bytes
 0:09:32
0:09:32
Dynamic Partition Pruning in Apache Spark
 0:06:32
0:06:32
Dynamic Partition Pruning | Spark Performance Tuning
 0:03:41
0:03:41
Apache Spark Datasource Mysql Partition
 0:14:43
0:14:43
Spark Partition | Hash Partitioner | Interview Question
 1:30:18
1:30:18
Apache Spark Core—Deep Dive—Proper Optimization Daniel Tomes Databricks
 0:08:32
0:08:32
Wildcard path and partition values in Apache Spark SQL
 0:04:25
0:04:25
Hash Partitioning vs Range Partitioning | Spark Interview questions
 0:11:06
0:11:06
Spark Tutorial: Partition Window
 0:05:52
0:05:52
35. Databricks & Spark: Interview Question - Shuffle Partition
 0:15:26
0:15:26
Apache Spark 3 | New Feature | Performance Optimization | Dynamic Partition Pruning
 0:05:53
0:05:53
46. Databricks | Spark | Pyspark | Number of Records per Partition in Dataframe
Комментарии