filmov
tv
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Показать описание
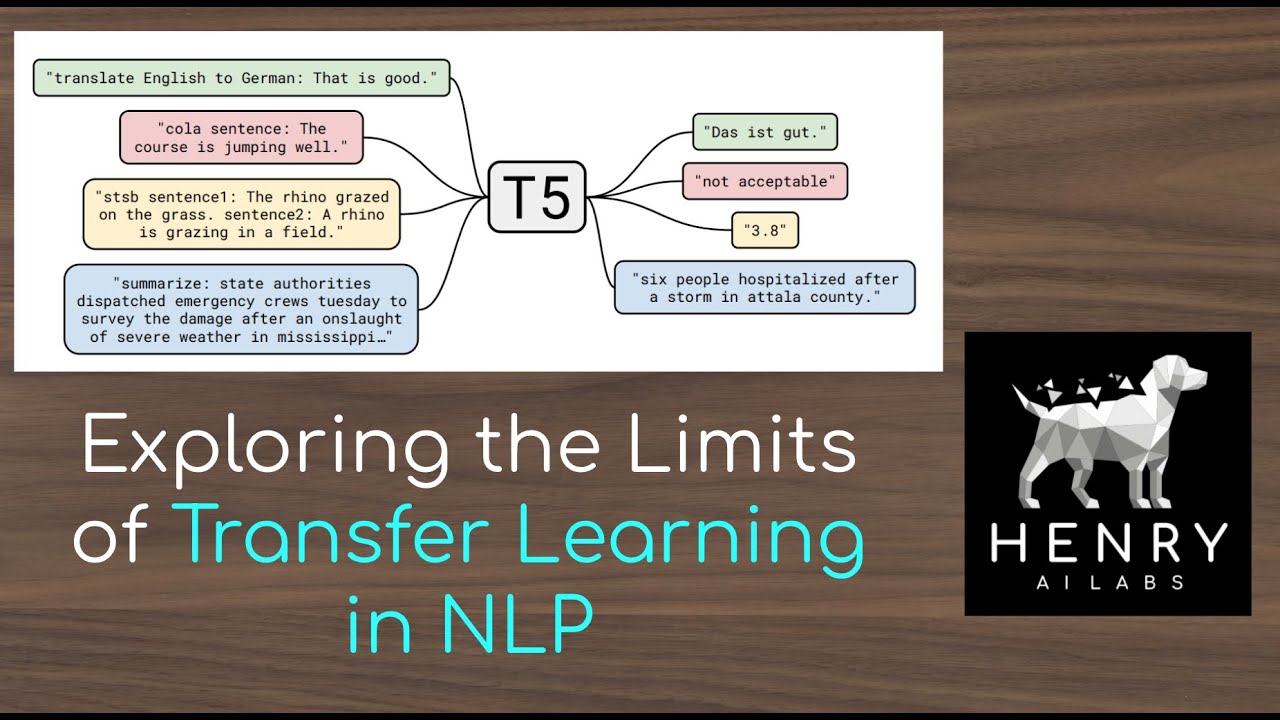
This video explores the T5 large-scale study on Transfer Learning. This paper takes apart many different factors of the Pre-Training then Fine-Tuning pipeline for NLP. This involves Auto-Regressive Language Modeling vs. BERT-Style Masked Language Modeling and XLNet-style shuffling, as well as the impact of dataset composition, size, and how to best use more computation. Thanks for watching and please check out Machine Learning Street Talk where Tim Scarfe, Yannic Kilcher and I discuss this paper!
Paper Links:
Thanks for watching! Please Subscribe!
Paper Links:
Thanks for watching! Please Subscribe!
 1:40:09
1:40:09
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
 0:12:47
0:12:47
T5: Exploring Limits of Transfer Learning with Text-to-Text Transformer (Research Paper Walkthrough)
 0:23:43
0:23:43
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
 1:04:19
1:04:19
Colin Raffel: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
![[Paper Review] Exploring](https://i.ytimg.com/vi/sfEfCe9Iea8/hqdefault.jpg) 0:26:32
0:26:32
[Paper Review] Exploring the Limits of Transfer Learning with a Unified Text to Text Transformer
 0:30:04
0:30:04
Team 12 - Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
 0:14:19
0:14:19
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (reading papers)
![[Audio notes] T5](https://i.ytimg.com/vi/AFcEGugRzIs/hqdefault.jpg) 0:37:06
0:37:06
[Audio notes] T5 - Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
 0:50:19
0:50:19
LLM: Exploring the Limits of Transfer Learning with a unified Text-to-Text Transformer (T5)
 0:41:22
0:41:22
PR-216: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
 0:00:39
0:00:39
What is T5 Model?
 0:03:47
0:03:47
Pushing NLP Boundaries: The Power of T5's Unified Text to Text Transformer
 1:08:15
1:08:15
An introduction to transfer learning in NLP and HuggingFace with Thomas Wolf
 0:29:47
0:29:47
The Limits of NLP
 0:09:42
0:09:42
Limits of Transfer Learning (LOD 2020)
 0:00:57
0:00:57
Can you solve this 150 years old puzzle? #shorts
 0:02:09
0:02:09
Hallucinations in Language Models: Critical Considerations
 0:00:54
0:00:54
Does PayPal have transfer limits?
 0:02:15
0:02:15
Are there any limits on how much money can be transferred from a debit card to another bank account?
 0:00:08
0:00:08
I’m off limits when I’m crafting.✨ Who can relate? 🙋🏼♀️ #craft #craftroom #painting #diy #crafty...
 0:50:42
0:50:42
Are Transformers Good Learners? Exploring the Limits of Transformer Training [ LingMon #175 ]
 0:01:14
0:01:14
New transistor research: Exploring the limits of miniaturisation
 0:15:50
0:15:50
T5 and Flan T5 Tutorial
 0:09:56
0:09:56
Exploring the Limits of Chemical Space
Комментарии