filmov
tv
How to explode an array of strings into multiple columns using Spark

Показать описание
Learn how to efficiently `explode` an array of strings in a Spark DataFrame to achieve a desired column format, suitable for variable length lists.
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Spark explode array of string to columns
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Exploring Arrays in Spark: Transforming DataFrames with the explode Function
Working with data in Spark can sometimes feel like solving a puzzle, especially when it comes to transforming arrays within DataFrames. In this post, we'll tackle a common problem: how to take an array of strings in a Spark DataFrame and explode it into separate columns. This transformation can help improve data readability and make it easier to analyze.
The Problem
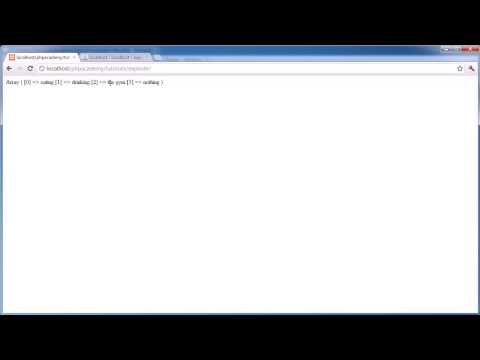
Imagine you have a DataFrame that includes an array of strings structured like this:
[[See Video to Reveal this Text or Code Snippet]]
Your goal is to transform this structure into a cleaner format where each unique key from the array becomes its own column, associated with its respective id. The desired output should look as follows:
[[See Video to Reveal this Text or Code Snippet]]
The Solution
The transformation needed here involves a combination of Spark functions, specifically explode and pivot. Here’s how to break down the process step-by-step:
Step 1: Setup
Before we dive into the coding part, ensure you have a dataset loaded into a DataFrame named input_df. In our example, we are using PySpark, but this method can easily be translated into Java or Scala because of their similar APIs.
Step 2: Explode the Array
The first step in transforming our DataFrame is to explode the array_column. This step expands the arrays into individual rows. In our case, it will turn each id entry into separate rows for each element in the array.
Step 3: Split the Strings
After exploding the array, we need to split each string using the colon (:) as a delimiter. This allows us to create two new columns:
col_name: The key from the string (e.g., a, b, c)
col_val: The numeric value associated with that key (e.g., 123, 125)
Step 4: Group and Pivot the Data
The final step involves grouping by id and pivoting the data so that each unique col_name becomes a column. We'll use the maximum value for each pivot column to obtain the desired structure of our DataFrame.
The Code
Here’s how the code looks in PySpark:
[[See Video to Reveal this Text or Code Snippet]]
Conclusion
By following these steps, you can efficiently transform an array of strings in a Spark DataFrame into a more structured format with multiple columns. This process not only enhances data readability but also paves the way for more straightforward analysis and reporting. Whether you’re using PySpark, Java, or Scala, the principles remain the same.
Give this a try in your Spark application, and see how it improves your data handling!
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Spark explode array of string to columns
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Exploring Arrays in Spark: Transforming DataFrames with the explode Function
Working with data in Spark can sometimes feel like solving a puzzle, especially when it comes to transforming arrays within DataFrames. In this post, we'll tackle a common problem: how to take an array of strings in a Spark DataFrame and explode it into separate columns. This transformation can help improve data readability and make it easier to analyze.
The Problem
Imagine you have a DataFrame that includes an array of strings structured like this:
[[See Video to Reveal this Text or Code Snippet]]
Your goal is to transform this structure into a cleaner format where each unique key from the array becomes its own column, associated with its respective id. The desired output should look as follows:
[[See Video to Reveal this Text or Code Snippet]]
The Solution
The transformation needed here involves a combination of Spark functions, specifically explode and pivot. Here’s how to break down the process step-by-step:
Step 1: Setup
Before we dive into the coding part, ensure you have a dataset loaded into a DataFrame named input_df. In our example, we are using PySpark, but this method can easily be translated into Java or Scala because of their similar APIs.
Step 2: Explode the Array
The first step in transforming our DataFrame is to explode the array_column. This step expands the arrays into individual rows. In our case, it will turn each id entry into separate rows for each element in the array.
Step 3: Split the Strings
After exploding the array, we need to split each string using the colon (:) as a delimiter. This allows us to create two new columns:
col_name: The key from the string (e.g., a, b, c)
col_val: The numeric value associated with that key (e.g., 123, 125)
Step 4: Group and Pivot the Data
The final step involves grouping by id and pivoting the data so that each unique col_name becomes a column. We'll use the maximum value for each pivot column to obtain the desired structure of our DataFrame.
The Code
Here’s how the code looks in PySpark:
[[See Video to Reveal this Text or Code Snippet]]
Conclusion
By following these steps, you can efficiently transform an array of strings in a Spark DataFrame into a more structured format with multiple columns. This process not only enhances data readability but also paves the way for more straightforward analysis and reporting. Whether you’re using PySpark, Java, or Scala, the principles remain the same.
Give this a try in your Spark application, and see how it improves your data handling!
 0:02:58
0:02:58
 0:23:00
0:23:00
 0:01:28
0:01:28
 0:18:03
0:18:03
 0:03:12
0:03:12
 0:01:32
0:01:32
 0:08:35
0:08:35
 0:03:56
0:03:56
 0:01:57
0:01:57
 0:01:07
0:01:07
 0:01:34
0:01:34
 0:02:16
0:02:16
 0:01:44
0:01:44
 0:00:51
0:00:51
 0:01:56
0:01:56
 0:04:15
0:04:15
 0:22:01
0:22:01
 0:11:44
0:11:44
 0:01:24
0:01:24
 0:10:09
0:10:09
 0:14:50
0:14:50
 0:00:59
0:00:59
 0:06:25
0:06:25
 0:00:57
0:00:57