filmov
tv
Optimization Techniques - W2023 - Lecture 10 (Distributed Optimization & Non-Smooth Optimization)

Показать описание
The course "Optimization Techniques" (ENGG*6140, section 2) at the School of Engineering at the University of Guelph. Instructor: Benyamin Ghojogh
Lecture 10 continues the distributed optimization methods by reviewing ADMM introduced in the previous session. Then, we talk about how to make univariate/multivariate optimization problem distributed. An example of ADMM in image processing is also introduced. Then, we switch to non-smooth optimization. We start with lasso (l1 norm) optimization. Then, we review the various methods for solving non-smooth optimization. These methods include convex conjugate, Huber and pseudo-Huber functions, soft-thresholding and proximal methods, coordinate descent, and subgradient methods.
Chapters:
0:00 - Talking about project presentation
4:30 - Correcting a typo in Wolfe conditions for line-search
7:13 - Brief review of distributed optimization from previous session
12:33 - Use cases of distributed algorithms
14:34 - Making univariate optimization problem distributed
20:12 - Making multivariate optimization problem distributed
32:42 - Example of ADMM in image processing
44:22 - Important references in distributed optimization
48:00 - Non-smooth optimization (introduction)
50:27 - Lasso (l1 norm) regularization
1:01:33 - Convex conjugate
1:09:26 - Convex conjugate of l1 norm
1:15:01 - Gradient in terms of convex conjugate
1:17:33 - Proximity function and Huber function
1:25:23 - Huber and pseudo-Huber functions
1:33:21 - Soft-thresholding and proximal methods
1:38:31 - Coordinate descent
1:47:19 - Coordinate descent for l1 norm optimization
1:58:14 - Subgradient
2:04:15 - Subdifferential
2:06:47 - Subdifferential for l1 norm
2:11:33 - First-order optimality condition for non-smooth function
2:15:09 - Subgradient in example functions
2:18:23 - Subgradient method
2:22:00 - Stochastic subgradient method
2:23:23 - Projected subgradient method
2:24:32 - Important references in non-smooth optimization
2:29:13 - Talking about the next sessions
Lecture 10 continues the distributed optimization methods by reviewing ADMM introduced in the previous session. Then, we talk about how to make univariate/multivariate optimization problem distributed. An example of ADMM in image processing is also introduced. Then, we switch to non-smooth optimization. We start with lasso (l1 norm) optimization. Then, we review the various methods for solving non-smooth optimization. These methods include convex conjugate, Huber and pseudo-Huber functions, soft-thresholding and proximal methods, coordinate descent, and subgradient methods.
Chapters:
0:00 - Talking about project presentation
4:30 - Correcting a typo in Wolfe conditions for line-search
7:13 - Brief review of distributed optimization from previous session
12:33 - Use cases of distributed algorithms
14:34 - Making univariate optimization problem distributed
20:12 - Making multivariate optimization problem distributed
32:42 - Example of ADMM in image processing
44:22 - Important references in distributed optimization
48:00 - Non-smooth optimization (introduction)
50:27 - Lasso (l1 norm) regularization
1:01:33 - Convex conjugate
1:09:26 - Convex conjugate of l1 norm
1:15:01 - Gradient in terms of convex conjugate
1:17:33 - Proximity function and Huber function
1:25:23 - Huber and pseudo-Huber functions
1:33:21 - Soft-thresholding and proximal methods
1:38:31 - Coordinate descent
1:47:19 - Coordinate descent for l1 norm optimization
1:58:14 - Subgradient
2:04:15 - Subdifferential
2:06:47 - Subdifferential for l1 norm
2:11:33 - First-order optimality condition for non-smooth function
2:15:09 - Subgradient in example functions
2:18:23 - Subgradient method
2:22:00 - Stochastic subgradient method
2:23:23 - Projected subgradient method
2:24:32 - Important references in non-smooth optimization
2:29:13 - Talking about the next sessions
 0:12:39
0:12:39
Premature Optimization
 0:11:46
0:11:46
7 Crucial Tips to Optimize your PC For Music Production in 2023
 0:03:44
0:03:44
The Ugly Truth of Nvidia Control Panel Optimization Guides
 0:11:23
0:11:23
8 React Js performance optimization techniques YOU HAVE TO KNOW!
 0:37:55
0:37:55
Google My Business Profile Optimization - Ultimate Tutorial for 2023 (Every Secret Revealed!)
 0:00:41
0:00:41
How to Improve Your Website SEO with 5 EASY Steps - SEO Optimization - B2B Marketing 2023
 0:40:25
0:40:25
AWS re:Invent 2023 - What’s new with AWS cost optimization (COP204)
 0:40:47
0:40:47
The ONLY Windows PC OPTIMIZATION Guide You Will EVER Need In 2024
 0:17:13
0:17:13
FULL NETWORK OPTIMIZATION GUIDE (2023)
 0:40:16
0:40:16
THE ONLY WINDOWS PC OPTIMIZATION GUIDE YOU WILL EVER NEED IN 2023
 0:11:13
0:11:13
How To Optimize Your Google Ads Campaign In 2024 (Full Guide With Real Results)
 0:11:00
0:11:00
How to Optimize Your Amazon Listing (FULL Amazon Listing Optimization 2023)
 0:25:43
0:25:43
Optimization Techniques Introduction
 0:00:48
0:00:48
Maximize your chances of getting hired with these speaking optimization techniques
 0:56:21
0:56:21
AWS re:Invent 2023 - Smart savings: Amazon EC2 cost-optimization strategies (CMP211)
 0:19:40
0:19:40
SEO For Beginners: A Basic Search Engine Optimization Tutorial for Higher Google Rankings
 0:07:50
0:07:50
Optimizing Rendering Performance in React
 0:00:30
0:00:30
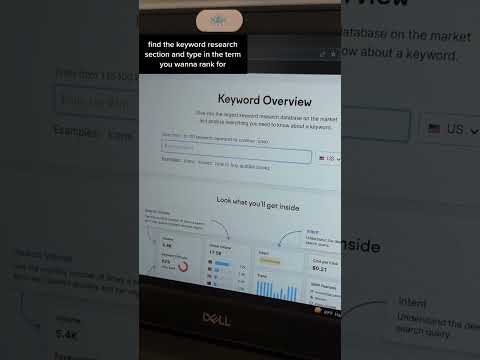
The Basics of Keyword Research | Website SEO Optimization Tips | SEMrush tutorial | #shorts
 0:51:17
0:51:17
Dmitriy Morozov (01/18/2023): Topological Optimization with Big Steps
 0:17:40
0:17:40
How to Optimize Performance in Unreal Engine 5
 0:11:13
0:11:13
How to Optimize Windows 10 For GAMING & Performance in 2024 The Ultimate GUIDE (Updated)
 0:13:48
0:13:48
Upwork Profile Optimization Tips and Tricks in 2023 | Upwork Course
 0:08:41
0:08:41
Google Ads Optimization 2023 (5 Keys For MAX Results)
 0:15:35
0:15:35
Yoast SEO - How To Optimize a Page All Green Bullets 2023
Комментарии