filmov
tv
Introduction to Regularization - Machine Learning and Pattern Recognition

Показать описание
In mathematics, statistics, finance, computer science, particularly in machine learning and inverse problems, regularization is a process that changes the result answer to be "simpler". It is often used to obtain results for ill-posed problems or to prevent overfitting.
Although regularization procedures can be divided in many ways, one particular delineation is particularly helpful:
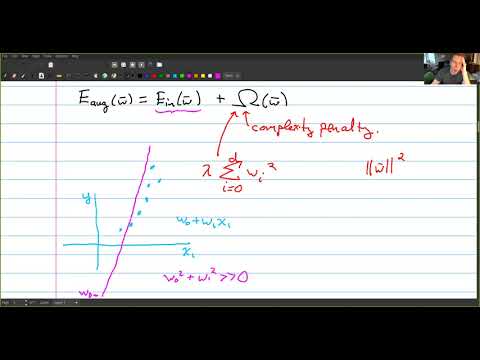
Explicit regularization is regularization whenever one explicitly adds a term to the optimization problem. These terms could be priors, penalties, or constraints. Explicit regularization is commonly employed with ill-posed optimization problems. The regularization term, or penalty, imposes a cost on the optimization function to make the optimal solution unique.
Implicit regularization is all other forms of regularization. This includes, for example, early stopping, using a robust loss function, and discarding outliers. Implicit regularization is essentially ubiquitous in modern machine learning approaches, including stochastic gradient descent for training deep neural networks, and ensemble methods (such as random forests and gradient boosted trees).
In explicit regularization, independent of the problem or model, there is always a data term, that corresponds to a likelihood of the measurement and a regularization term that corresponds to a prior. By combining both using Bayesian statistics, one can compute a posterior, that includes both information sources and therefore stabilizes the estimation process. By trading off both objectives, one chooses to be more addictive to the data or to enforce generalization (to prevent overfitting). There is a whole research branch dealing with all possible regularizations. The work flow usually is, that one tries a specific regularization and then figures out the probability density that corresponds to that regularization to justify the choice. It can also be physically motivated by common sense or intuition.
In machine learning, the data term corresponds to the training data and the regularization is either the choice of the model or modifications to the algorithm. It is always intended to reduce the generalization error, i.e. the error score with the trained model on the evaluation set and not the training data.
One of the earliest uses of regularization is Tikhonov regularization, related to the method of least squares.
Although regularization procedures can be divided in many ways, one particular delineation is particularly helpful:
Explicit regularization is regularization whenever one explicitly adds a term to the optimization problem. These terms could be priors, penalties, or constraints. Explicit regularization is commonly employed with ill-posed optimization problems. The regularization term, or penalty, imposes a cost on the optimization function to make the optimal solution unique.
Implicit regularization is all other forms of regularization. This includes, for example, early stopping, using a robust loss function, and discarding outliers. Implicit regularization is essentially ubiquitous in modern machine learning approaches, including stochastic gradient descent for training deep neural networks, and ensemble methods (such as random forests and gradient boosted trees).
In explicit regularization, independent of the problem or model, there is always a data term, that corresponds to a likelihood of the measurement and a regularization term that corresponds to a prior. By combining both using Bayesian statistics, one can compute a posterior, that includes both information sources and therefore stabilizes the estimation process. By trading off both objectives, one chooses to be more addictive to the data or to enforce generalization (to prevent overfitting). There is a whole research branch dealing with all possible regularizations. The work flow usually is, that one tries a specific regularization and then figures out the probability density that corresponds to that regularization to justify the choice. It can also be physically motivated by common sense or intuition.
In machine learning, the data term corresponds to the training data and the regularization is either the choice of the model or modifications to the algorithm. It is always intended to reduce the generalization error, i.e. the error score with the trained model on the evaluation set and not the training data.
One of the earliest uses of regularization is Tikhonov regularization, related to the method of least squares.
 0:19:21
0:19:21
Machine Learning Tutorial Python - 17: L1 and L2 Regularization | Lasso, Ridge Regression
 0:20:27
0:20:27
Regularization Part 1: Ridge (L2) Regression
 0:00:57
0:00:57
Introduction to Regularization
 0:03:25
0:03:25
Introduction to Regularization
 0:11:42
0:11:42
Introduction to Regularization - Machine Learning and Pattern Recognition
 0:20:17
0:20:17
Tutorial 27- Ridge and Lasso Regression Indepth Intuition- Data Science
 0:15:31
0:15:31
Regularization in machine learning | L1 and L2 Regularization | Lasso and Ridge Regression
 0:11:40
0:11:40
Regularization in a Neural Network | Dealing with overfitting
 0:47:06
0:47:06
How to design a Linear regression Model 2024 edition (Revised 2024-3/12)-I/II
 0:00:59
0:00:59
Regularization
 0:12:00
0:12:00
L1 and L2 Regularization in Machine Learning: Easy Explanation for Data Science Interviews
 0:08:11
0:08:11
Introduction to Regularization: Ridge and Lasso (5.1)
 0:02:21
0:02:21
Regularization
 0:29:44
0:29:44
Regularization In Machine Learning | Regularization Example | Machine Learning Tutorial |Simplilearn
 0:12:44
0:12:44
Regularization Lasso (L1) and Ridge (L2) | A beginner guide
 0:05:54
0:05:54
Linear Regression and Regularization Introduction
 0:12:44
0:12:44
Regularization - Explained!
 0:04:57
0:04:57
Regularization
 0:21:14
0:21:14
Regulaziation in Machine Learning | L1 and L2 Regularization | Data Science | Edureka
 0:20:56
0:20:56
Machine Learning 18: Regularization
 0:06:36
0:06:36
Machine Learning Fundamentals: Bias and Variance
 0:00:51
0:00:51
What is Regularization in Machine Learning?
 0:15:05
0:15:05
Introduction to Regularization Techniques
 0:07:35
0:07:35
Regularization 1
Комментарии