filmov
tv
Training Distributed Deep Recurrent Neural Networks with Mixed Precision on GPU Clusters

Показать описание
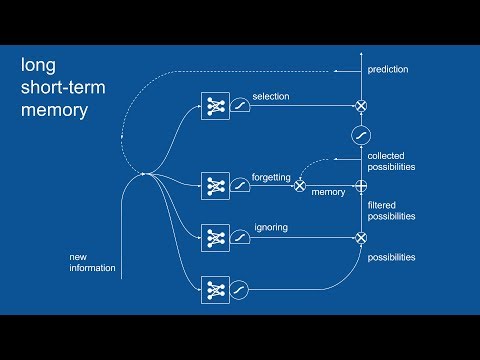
Alexey Svyatkovskiy is a Data Scientist at Microsoft. In this talk, we evaluate training of deep recurrent neural networks with half-precision floats on Pascal and Volta GPUs. We implement a distributed, data-parallel, synchronous training algorithm by integrating TensorFlow and CUDA-aware MPI to enable execution across multiple GPU nodes and making use of high-speed interconnects. We introduce a learning rate schedule facilitating neural network convergence at up to O(100) workers.
About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
 0:30:59
0:30:59
 0:16:37
0:16:37
 0:07:47
0:07:47
 0:09:51
0:09:51
 0:16:05
0:16:05
 0:16:00
0:16:00
 1:01:34
1:01:34
 0:10:54
0:10:54
 0:00:46
0:00:46
 0:08:19
0:08:19
 1:13:09
1:13:09
 0:15:25
0:15:25
 0:10:13
0:10:13
 0:06:55
0:06:55
 0:00:35
0:00:35
 0:05:21
0:05:21
 0:07:09
0:07:09
 0:15:52
0:15:52
 1:15:59
1:15:59
 0:34:08
0:34:08
 0:26:14
0:26:14
 0:01:00
0:01:00
 0:37:45
0:37:45
 0:00:16
0:00:16