filmov
tv
Understanding Character Encoding Issues in Java: How to Fix Reader Misinterpretations

Показать описание
Discover why your Java reader is misreading characters and learn how to solve encoding issues with practical code examples and tips.
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Why is reader in java reading characters wrong?
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Understanding Character Encoding Issues in Java: How to Fix Reader Misinterpretations
When working with files in Java, you might encounter unexpected behavior while reading characters. A common issue arises when characters are misrepresented or shown as 65533, which typically signifies a problem with encoding. In this post, we’ll explore the root of this issue, how to diagnose it, and how to effectively resolve it.
The Problem: Misreading Characters
Imagine you’re attempting to read a custom file type (.xs) that contains special characters, but instead, you receive odd integer outputs like 65533. This might leave you wondering if the problem lies in your code or the encoding of the file.
Consider the following example:
[[See Video to Reveal this Text or Code Snippet]]
Diagnosing the Issue
The primary cause of reading characters incorrectly often relates to the encoding method used when processing the file:
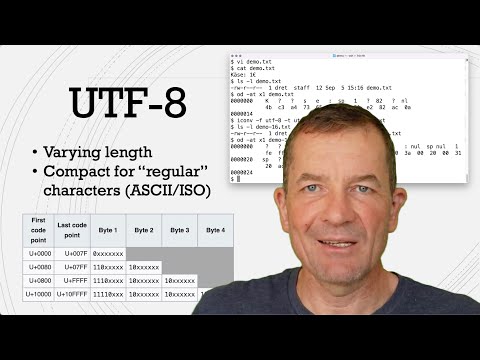
Default Encoding Assumption: By default, the Java FileReader uses the system’s default character encoding. If the actual file is encoded differently (like UTF-8), characters may not match up correctly.
Replacement Character (65533): This character signifies that the reader cannot interpret a byte sequence correctly, indicating an encoding mismatch.
The Solution: Using Specified Encoding
To resolve this issue, you should explicitly define the encoding when reading the file. Instead of using FileReader, utilize InputStreamReader along with a specified charset.
Updated Code Example
Here’s how to modify your code accordingly:
[[See Video to Reveal this Text or Code Snippet]]
Key Points:
Use InputStreamReader: This allows you to specify the encoding (in this case, UTF-8) which matches common file encodings.
Character Encoding: Make sure that the file is indeed saved in UTF-8. If the editor you’re using supports it, explicitly save your file in UTF-8 format.
Conclusion
Character encoding issues can lead to frustrating debugging experiences, yet they are often resolved by simply specifying the correct encoding format. By using InputStreamReader with UTF-8, you can ensure that your Java application accurately reads and represents all necessary characters.
Try updating your file reading code as demonstrated, and you should see far more accurate outputs. If you ensure proper file encoding from the outset, addressing these issues will be simpler and more predictable in the future!
---
Visit these links for original content and any more details, such as alternate solutions, latest updates/developments on topic, comments, revision history etc. For example, the original title of the Question was: Why is reader in java reading characters wrong?
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
Understanding Character Encoding Issues in Java: How to Fix Reader Misinterpretations
When working with files in Java, you might encounter unexpected behavior while reading characters. A common issue arises when characters are misrepresented or shown as 65533, which typically signifies a problem with encoding. In this post, we’ll explore the root of this issue, how to diagnose it, and how to effectively resolve it.
The Problem: Misreading Characters
Imagine you’re attempting to read a custom file type (.xs) that contains special characters, but instead, you receive odd integer outputs like 65533. This might leave you wondering if the problem lies in your code or the encoding of the file.
Consider the following example:
[[See Video to Reveal this Text or Code Snippet]]
Diagnosing the Issue
The primary cause of reading characters incorrectly often relates to the encoding method used when processing the file:
Default Encoding Assumption: By default, the Java FileReader uses the system’s default character encoding. If the actual file is encoded differently (like UTF-8), characters may not match up correctly.
Replacement Character (65533): This character signifies that the reader cannot interpret a byte sequence correctly, indicating an encoding mismatch.
The Solution: Using Specified Encoding
To resolve this issue, you should explicitly define the encoding when reading the file. Instead of using FileReader, utilize InputStreamReader along with a specified charset.
Updated Code Example
Here’s how to modify your code accordingly:
[[See Video to Reveal this Text or Code Snippet]]
Key Points:
Use InputStreamReader: This allows you to specify the encoding (in this case, UTF-8) which matches common file encodings.
Character Encoding: Make sure that the file is indeed saved in UTF-8. If the editor you’re using supports it, explicitly save your file in UTF-8 format.
Conclusion
Character encoding issues can lead to frustrating debugging experiences, yet they are often resolved by simply specifying the correct encoding format. By using InputStreamReader with UTF-8, you can ensure that your Java application accurately reads and represents all necessary characters.
Try updating your file reading code as demonstrated, and you should see far more accurate outputs. If you ensure proper file encoding from the outset, addressing these issues will be simpler and more predictable in the future!
 0:10:54
0:10:54
 0:09:37
0:09:37
 0:03:29
0:03:29
 0:02:54
0:02:54
 0:01:46
0:01:46
 0:09:37
0:09:37
 0:01:28
0:01:28
 0:13:57
0:13:57
 0:06:15
0:06:15
 0:01:27
0:01:27
 0:06:04
0:06:04
 0:03:16
0:03:16
 0:03:27
0:03:27
 0:00:54
0:00:54
 0:03:05
0:03:05
 0:15:44
0:15:44
 0:02:40
0:02:40
 0:32:45
0:32:45
 0:01:28
0:01:28
 0:01:46
0:01:46
 0:01:52
0:01:52
 0:01:19
0:01:19
 0:01:18
0:01:18
 0:01:34
0:01:34