filmov
tv
What is Q* | Reinforcement learning 101 & Hypothesis

Показать описание
🔗 Links
👋🏻 About Me
#chatgpt #gpt4 #gpt5 #ai #artificialintelligence #tutorial #stepbystep #openai #llm #chatgpt #largelanguagemodels #largelanguagemodel #agent #reinforcementlearning
👋🏻 About Me
#chatgpt #gpt4 #gpt5 #ai #artificialintelligence #tutorial #stepbystep #openai #llm #chatgpt #largelanguagemodels #largelanguagemodel #agent #reinforcementlearning
 0:11:44
0:11:44
What is Q* | Reinforcement learning 101 & Hypothesis
 0:02:54
0:02:54
What is Q
 0:08:38
0:08:38
Q-Learning Explained - A Reinforcement Learning Technique
 0:09:27
0:09:27
Q Learning Explained (tutorial)
 0:06:48
0:06:48
Q-Learning Explained - Reinforcement Learning Tutorial
 0:02:28
0:02:28
Reinforcement Learning Basics
 0:11:28
0:11:28
Reinforcement Learning: Crash Course AI #9
 0:35:35
0:35:35
Q-Learning: Model Free Reinforcement Learning and Temporal Difference Learning
 0:11:44
0:11:44
Understanding Reinforcement Learning Algorithms: The Progress from Basic Q-learning to P
 0:10:41
0:10:41
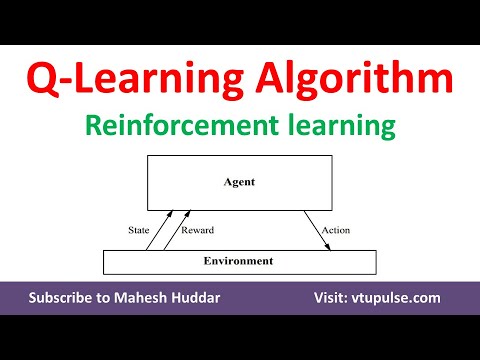
Q Learning Algorithm | Reinforcement learning | Machine Learning by Dr. Mahesh Huddar
 0:11:11
0:11:11
#1. Q Learning Algorithm Solved Example | Reinforcement Learning | Machine Learning by Mahesh Huddar
 0:10:50
0:10:50
Deep Q-Learning - Combining Neural Networks and Reinforcement Learning
 0:24:55
0:24:55
Q Learning In Reinforcement Learning | Q Learning Example | Machine Learning Tutorial | Simplilearn
 0:08:25
0:08:25
Reinforcement Learning from scratch
 0:24:50
0:24:50
Overview of Deep Reinforcement Learning Methods
 0:36:26
0:36:26
A friendly introduction to deep reinforcement learning, Q-networks and policy gradients
 0:08:56
0:08:56
Introduction to Reinforcement Learning | Scope of Reinforcement Learning by Mahesh Huddar
 1:07:30
1:07:30
MIT 6.S091: Introduction to Deep Reinforcement Learning (Deep RL)
 0:06:27
0:06:27
Machine Learning #65 - Reinforcement Learning #3 - Q-Learning
 0:01:55
0:01:55
Robot trains with Q-Learning and an artificial neural network (reinforcement learning)
 0:16:46
0:16:46
Reinforcement Learning Made Simple - Q-Values
 0:32:19
0:32:19
Deep Q Learning w/ DQN - Reinforcement Learning p.5
 0:28:39
0:28:39
Temporal Difference Learning (including Q-Learning) | Reinforcement Learning Part 4
 0:57:33
0:57:33
MIT 6.S191 (2023): Reinforcement Learning
Комментарии