filmov
tv
AWS Tutorials – Building ETL Pipeline using AWS Glue and Step Functions

Показать описание
In AWS, ETL pipelines can be built using AWS Glue Job and Glue Crawler. AWS Glue Jobs are responsible for data transformation while Crawlers are responsible for data catalog. Amazon Step Functions is one approach to create such pipelines. In this tutorial, learn how to use Step Functions build ETL pipeline in AWS.
 0:38:31
0:38:31
AWS Tutorials – Building ETL Pipeline using AWS Glue and Step Functions
 0:06:29
0:06:29
Building ETL Pipelines on AWS
 0:06:01
0:06:01
Back to Basics: Building an Event Driven Serverless ETL Pipeline on AWS
 0:52:42
0:52:42
AWS Tutorials – Building Event Based AWS Glue ETL Pipeline
 0:10:41
0:10:41
How to build an ETL pipeline with Python | Data pipeline | Export from SQL Server to PostgreSQL
 0:09:21
0:09:21
What is ETL Pipeline? | ETL Pipeline Tutorial | How to Build ETL Pipeline | Simplilearn
 0:43:57
0:43:57
AWS Tutorials - Methods of Building AWS Glue ETL Pipeline
 0:22:35
0:22:35
AWS Hands-On: ETL with Glue and Athena
 1:49:49
1:49:49
How to build and automate a python ETL pipeline with airflow on AWS EC2 | Data Engineering Project
 0:23:27
0:23:27
AWS Tutorials - Build Enterprise Scale Python ETL Jobs using AWS Glue on Ray
 0:38:28
0:38:28
ETL | Incremental Data Load from Amazon S3 Bucket to Amazon Redshift Using AWS Glue | Datawarehouse
 0:41:33
0:41:33
AWS Tutorials - Data Quality Check in AWS Glue ETL Pipeline
 0:41:30
0:41:30
AWS Tutorials – ETL Pipeline with Multiple Files Ingestion in S3
 0:21:52
0:21:52
AWS Glue Tutorial | Getting Started with AWS Glue ETL | AWS Tutorial for Beginners | Edureka
 0:37:55
0:37:55
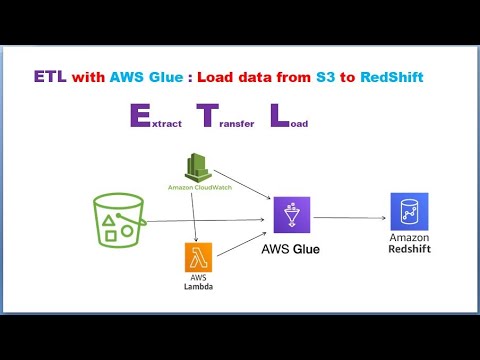
ETL | AWS Glue | AWS S3 | Load Data from AWS S3 to Amazon RedShift
 0:41:30
0:41:30
AWS Glue Tutorial for Beginners [FULL COURSE in 45 mins]
 0:25:57
0:25:57
AWS Tutorials - Joining Datasets in AWS Glue ETL Job
 0:11:30
0:11:30
How to build and automate your Python ETL pipeline with Airflow | Data pipeline | Python
 0:23:22
0:23:22
AWS Tutorials - Using Glue Job ETL from REST API Source to Amazon S3 Bucket Destination
 0:17:58
0:17:58
AWS Data Engineer Project | AWS Glue | ETL in AWS
 0:15:49
0:15:49
How to create and run a Glue ETL Job | Transform S3 Data using AWS Glue ETL| AWS Glue ETL Pipeline
 0:09:48
0:09:48
What Is DBT and Why Is It So Popular - Intro To Data Infrastructure Part 3
 0:10:34
0:10:34
What is Data Pipeline | How to design Data Pipeline ? - ETL vs Data pipeline (2024)
 0:15:32
0:15:32
Building ETL Pipelines Using Cloud Dataflow in GCP
Комментарии