filmov
tv
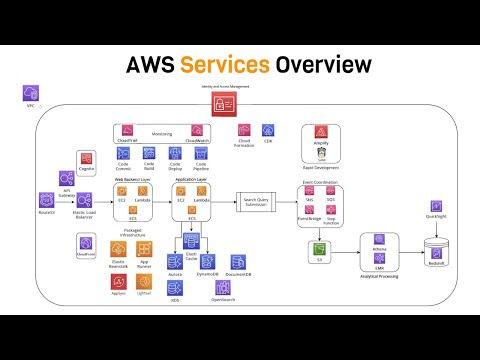
AWS Tutorials – Building Event Based AWS Glue ETL Pipeline

Показать описание
AWS Glue Pipelines are responsible to ingest data in the data platform or data lake and manage data transformation lifecycle from raw to cleansed to curated state. There are many methods to build such pipelines. In this video, you learn how to build event based ETL pipeline.
 0:52:42
0:52:42
AWS Tutorials – Building Event Based AWS Glue ETL Pipeline
 0:06:01
0:06:01
Back to Basics: Building an Event Driven Serverless ETL Pipeline on AWS
 0:15:49
0:15:49
Event Driven Architectures vs Workflows (with AWS Services!)
 0:26:13
0:26:13
AWS Project: Architect and Build an End-to-End AWS Web Application from Scratch, Step by Step
 0:19:54
0:19:54
Event Driven Architecture | AWS S3 . SNS . SQS . Lambda
 0:27:56
0:27:56
AWS re:Invent 2020: Building event-driven applications with Amazon EventBridge
 0:11:52
0:11:52
AMAZON EVENTBRIDGE tutorial with AWS CDK - Building an Event-Driven Application
 0:50:49
0:50:49
AWS re:Invent 2022 - Building next-gen applications with event-driven architectures (API311-R)
 0:52:17
0:52:17
AWS Certified Security Specialty Exam Practice Questions - ANALYSIS P6 (SCS-C02)
 0:52:58
0:52:58
AWS re:Invent 2019: [NEW LAUNCH!] Building event-driven architectures w/ Amazon EventBridge (API320)
 0:27:27
0:27:27
AMAZON EVENTBRIDGE tutorial - Build your SERVERLESS event-driven app with AWS SAM
 0:41:30
0:41:30
AWS Tutorials – ETL Pipeline with Multiple Files Ingestion in S3
 0:38:31
0:38:31
AWS Tutorials – Building ETL Pipeline using AWS Glue and Step Functions
 0:08:47
0:08:47
AWS EventBridge Tutorial | AWS EventBridge Theory and Demo | CloudWatch Events | AWS Tutorials
 0:35:48
0:35:48
AWS re:Invent 2022 - [NEW] EventBridge Pipes simplifies connecting event-driven services (API206)
 0:01:12
0:01:12
AWS Event-Driven Architecture Explainer Video | Amazon Web Services
 0:53:45
0:53:45
AWS re:Invent 2022 - Building Serverlesspresso: Creating event-driven architectures (SVS312)
 0:43:57
0:43:57
AWS Tutorials - Methods of Building AWS Glue ETL Pipeline
 0:50:07
0:50:07
Intro to AWS - The Most Important Services To Learn
 0:27:51
0:27:51
AWS Step Functions + Lambda Tutorial - Step by Step Guide in the Workflow Studio
 0:37:55
0:37:55
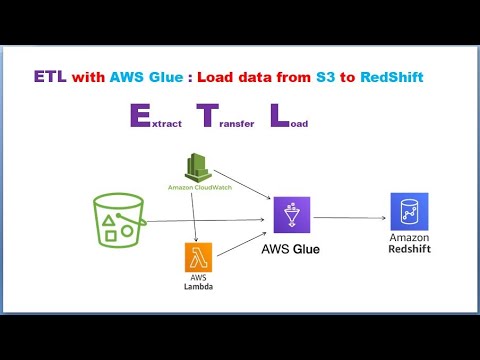
ETL | AWS Glue | AWS S3 | Load Data from AWS S3 to Amazon RedShift
 0:55:58
0:55:58
AWS re:Invent 2022 - Building observable applications with OpenTelemetry (BOA310)
 0:17:32
0:17:32
Serverless Web Application on AWS [S3, Lambda, SQS, DynamoDB and API Gateway]
 0:58:25
0:58:25
Building an Observability Solution with Amazon OpenSearch Service | AWS Events
Комментарии