filmov
tv
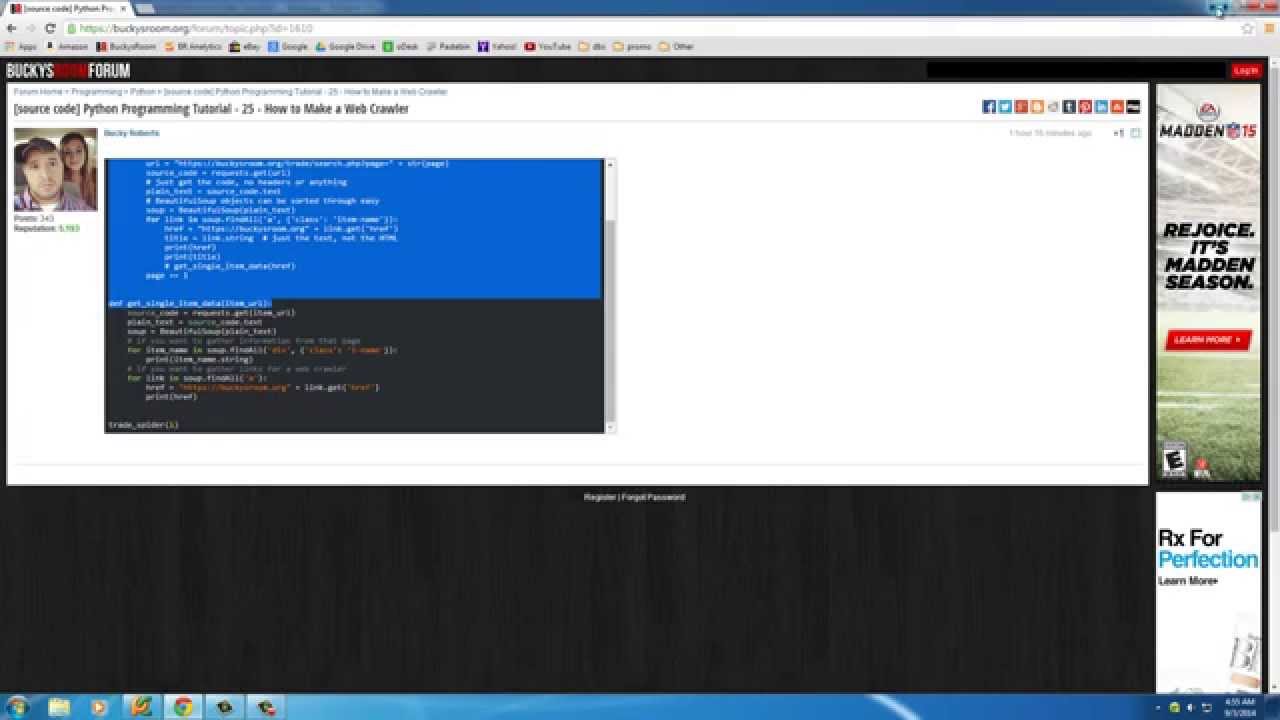
Python Programming Tutorial - 27 - How to Build a Web Crawler (3/3)
Показать описание
 0:08:17
0:08:17
Python Tutorial - 27. Multiprocessing Introduction
 0:11:21
0:11:21
Python Programming Tutorial - 27 - How to Build a Web Crawler (3/3)
 0:05:30
0:05:30
Python Programming Tutorial - 27: String Functions (Part-2)
 0:11:36
0:11:36
Python Tutorial for Beginners 27 - Python Encapsulation
 0:08:43
0:08:43
Try / Except | Python | Tutorial 27
 0:25:34
0:25:34
Python Tutorial 27 - Packages in Python
 0:10:02
0:10:02
#27 Python Tutorial for Beginners | Array values from User in Python | Search in Array
 0:06:57
0:06:57
P_27 Coding Exercise for Beginners in Python | Exercise 7 | Python Tutorials for Beginners
 0:46:27
0:46:27
Live with Reuven Lerner: How to Sort Anything with Python
 1:06:48
1:06:48
Learn Python Programming Tutorial Online Training by Durga Sir On 27-01-2018
 12:00:00
12:00:00
Python Full Course for free 🐍 (2024)
 0:09:28
0:09:28
Python Functions || Python Tutorial || Learn Python Programming
 0:09:05
0:09:05
Remove Element - Leetcode 27 - Python
 0:06:32
0:06:32
Python 3 Tutorial for Beginners #27 - Writing Files
 0:25:55
0:25:55
Transfer Learning | Deep Learning Tutorial 27 (Tensorflow, Keras & Python)
 4:26:52
4:26:52
Learn Python - Full Course for Beginners [Tutorial]
 4:40:00
4:40:00
Python for Beginners – Full Course [Programming Tutorial]
 0:07:09
0:07:09
Python Programming Tutorial - 8 - for
 0:03:38
0:03:38
Python Programming Tutorial - 17 - Flexible Number of Arguments
 1:00:06
1:00:06
Python for Beginners - Learn Python in 1 Hour
 0:09:09
0:09:09
Iterators, Iterables, and Itertools in Python || Python Tutorial || Learn Python Programming
 0:16:54
0:16:54
Selenium with Python Tutorial 27-Working with Cookies
 11:08:59
11:08:59
The complete guide to Python
 0:06:24
0:06:24
Pygame (Python Game Development) Tutorial - 27 - Centering Text
Комментарии