filmov
tv
Neural networks [5.1] : Restricted Boltzmann machine - definition

Показать описание
![Neural networks [5.1]](https://i.ytimg.com/vi/p4Vh_zMw-HQ/hqdefault.jpg) 0:12:17
0:12:17
Neural networks [5.1] : Restricted Boltzmann machine - definition
 0:04:52
0:04:52
Restricted Boltzmann Machines - Ep. 6 (Deep Learning SIMPLIFIED)
 0:12:12
0:12:12
Restricted Boltzmann Machine | Neural Network Tutorial | Deep Learning Tutorial | Edureka
![Neural networks [5.8]](https://i.ytimg.com/vi/iPuqoQih9xk/hqdefault.jpg) 0:09:19
0:09:19
Neural networks [5.8] : Restricted Boltzmann machine - extensions
 0:01:07
0:01:07
Restricted Boltzmann Machines in 60 seconds!
![Neural networks [5.7]](https://i.ytimg.com/vi/n26NdEtma8U/hqdefault.jpg) 0:08:15
0:08:15
Neural networks [5.7] : Restricted Boltzmann machine - example
 0:05:18
0:05:18
Deep Learning with Tensorflow - Initializing a Restricted Boltzmann Machine
 0:08:56
0:08:56
Introduction to Boltzmann Machines
![Neural networks [5.3]](https://i.ytimg.com/vi/e0Ts_7Y6hZU/hqdefault.jpg) 0:12:54
0:12:54
Neural networks [5.3] : Restricted Boltzmann machine - free energy
![Neural networks [5.2]](https://i.ytimg.com/vi/lekCh_i32iE/hqdefault.jpg) 0:18:32
0:18:32
Neural networks [5.2] : Restricted Boltzmann machine - inference
 0:04:56
0:04:56
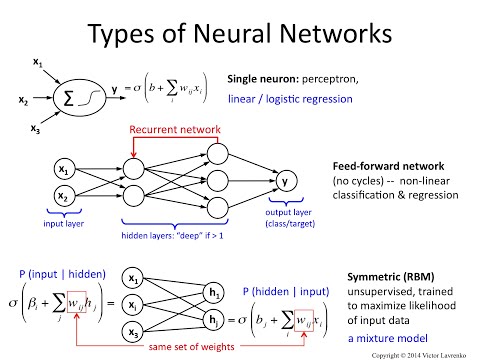
Neural Networks 5: feedforward, recurrent and RBM
 0:36:58
0:36:58
Restricted Boltzmann Machines (RBM) - A friendly introduction
 0:06:36
0:06:36
Neural Network - Learning Rules 5 - Boltzmann Learning Rule
 0:01:56
0:01:56
Deep Neural Network Introduction
![Neural networks [5.6]](https://i.ytimg.com/vi/S0kFFiHzR8M/hqdefault.jpg) 0:07:36
0:07:36
Neural networks [5.6] : Restricted Boltzmann machine - persistent CD
 0:06:19
0:06:19
Neuronale Netze #21 - (Restricted) Boltzmann Machines (Machine Learning #101)
 0:01:58
0:01:58
Deep Neural Network
![Neural networks [5.5]](https://i.ytimg.com/vi/wMb7cads0go/hqdefault.jpg) 0:11:10
0:11:10
Neural networks [5.5] : Restricted Boltzmann machine - contrastive divergence (parameter update)
 0:05:04
0:05:04
Deep Learning with Tensorflow - RBMs and Autoencoders
 0:16:10
0:16:10
Deep Learning Part - II (CS7015): Lec 18.3 Restricted Boltzmann Machines
 0:05:00
0:05:00
What are Autoencoders?
 0:09:15
0:09:15
#117: Scikit-learn 113:Unsupervised Learning 17:Neural Network Models
![Neural networks [4.1]](https://i.ytimg.com/vi/6dpGB60Q1Ts/hqdefault.jpg) 0:05:45
0:05:45
Neural networks [4.1] : Training CRFs - loss function
 1:13:13
1:13:13
Ali Ghodsi, Lec [7], Deep Learning , Restricted Boltzmann Machines (RBMs)
Комментарии