filmov
tv
Vectoring Words (Word Embeddings) - Computerphile

Показать описание
How do you represent a word in AI? Rob Miles reveals how words can be formed from multi-dimensional vectors - with some unexpected results.
08:06 - Yes, it's a rubber egg :)
Unicorn AI:
This video was filmed and edited by Sean Riley.
08:06 - Yes, it's a rubber egg :)
Unicorn AI:
This video was filmed and edited by Sean Riley.
 0:16:56
0:16:56
Vectoring Words (Word Embeddings) - Computerphile
 0:16:12
0:16:12
Word Embedding and Word2Vec, Clearly Explained!!!
 0:10:20
0:10:20
12.1: What is word2vec? - Programming with Text
 0:18:28
0:18:28
What is Word2Vec? A Simple Explanation | Deep Learning Tutorial 41 (Tensorflow, Keras & Python)
 0:03:22
0:03:22
Vector databases are so hot right now. WTF are they?
 0:04:23
0:04:23
Vector Databases simply explained! (Embeddings & Indexes)
 0:08:44
0:08:44
The Illustrated Word2vec - A Gentle Intro to Word Embeddings in Machine Learning
 0:15:10
0:15:10
Word Embedding - Natural Language Processing| Deep Learning
 0:07:45
0:07:45
Word embedding | natural language processing (NLP)
 0:05:59
0:05:59
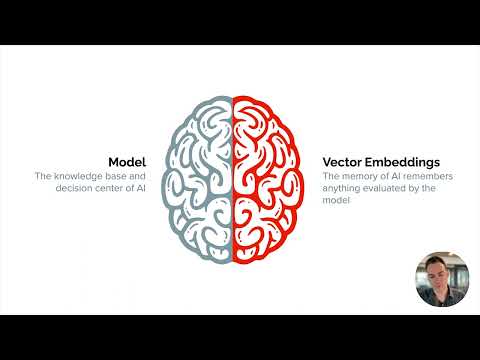
What are AI vector embeddings?
 0:09:57
0:09:57
Text Vectorization NLP | Vectorization using Python | Bag Of Words | Machine Learning
 0:00:56
0:00:56
AI Demystified: Word Embeddings
 0:07:57
0:07:57
Pre Trained Word Embeddings | Word2Vect, GloVe
 0:18:05
0:18:05
How AI 'Understands' Images (CLIP) - Computerphile
 0:18:00
0:18:00
Embeddings from Scratch!
 0:08:27
0:08:27
Natural Language Processing|TF-IDF Intuition| Text Prerocessing
 0:02:30
0:02:30
What Are Word Embeddings? | Aadil Ali
 0:01:24
0:01:24
LLM embeddings explained by Jerry Liu from LlamaIndex
 0:51:01
0:51:01
Intuition & Use-Cases of Embeddings in NLP & beyond
 2:17:25
2:17:25
L04 : Text and Embeddings: Introduction to NLP, Word Embeddings, Word2Vec
 0:01:35
0:01:35
Bag of Words - Intro to Machine Learning
 0:04:45
0:04:45
5 Ways To Generate Vector Embeddings
 0:10:36
0:10:36
Word Embeddings: Introduction
![[Classic] Word2Vec: Distributed](https://i.ytimg.com/vi/yexR53My2O4/hqdefault.jpg) 0:31:22
0:31:22
[Classic] Word2Vec: Distributed Representations of Words and Phrases and their Compositionality
Комментарии