filmov
tv
Ray Serve: Patterns of ML Models in Production

Показать описание
(Simon Mo, Anyscale)
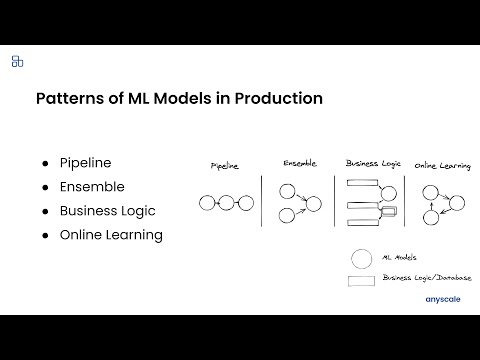
You trained a ML model, now what? The model needs to be deployed for online serving and offline processing. This talk walks through the journey of deploying your ML models in production. I will cover common deployment patterns backed by concrete use cases which are drawn from 100+ user interviews for Ray and Ray Serve. Lastly, I will cover how we built Ray Serve, a scalable model serving framework, from these learnings.
You trained a ML model, now what? The model needs to be deployed for online serving and offline processing. This talk walks through the journey of deploying your ML models in production. I will cover common deployment patterns backed by concrete use cases which are drawn from 100+ user interviews for Ray and Ray Serve. Lastly, I will cover how we built Ray Serve, a scalable model serving framework, from these learnings.
 0:25:12
0:25:12
Ray Serve: Patterns of ML Models in Production
 0:23:03
0:23:03
Introducing Ray Serve: Scalable and Programmable ML Serving Framework - Simon Mo, Anyscale
 0:25:42
0:25:42
Deploying Many Models Efficiently with Ray Serve
 0:26:19
0:26:19
TALK / Simon Mo / Patterns of ML Models in Production
 0:32:34
0:32:34
Ray Serve: Tutorial for Building Real Time Inference Pipelines
 0:30:08
0:30:08
Building Production AI Applications with Ray Serve
 1:10:43
1:10:43
Ray: A Framework for Scaling and Distributing Python & ML Applications
 0:41:59
0:41:59
Seamlessly Scaling your ML Pipelines with Ray Serve - Archit Kulkarni
 0:30:28
0:30:28
Enabling Cost-Efficient LLM Serving with Ray Serve
 1:49:44
1:49:44
Productionizing ML at scale with Ray Serve
 1:10:41
1:10:41
Introduction to Model Deployment with Ray Serve
 0:31:33
0:31:33
State of Ray Serve in 2.0
 0:41:35
0:41:35
Advanced Model Serving Techniques with Ray on Kubernetes - Andrew Sy Kim & Kai-Hsun Chen
 0:30:14
0:30:14
Multi-model composition with Ray Serve deployment graphs
 0:30:30
0:30:30
Faster Model Serving with Ray and Anyscale | Ray Summit 2024
 0:28:37
0:28:37
Leveraging the Possibilities of Ray Serve
 0:27:45
0:27:45
Scaling AI & Machine Learning Workloads With Ray on AWS, Kubernetes, & BERT
 3:20:32
3:20:32
Scalable machine learning workloads with Ray AI Runtime
 0:25:00
0:25:00
KubeRay: A Ray cluster management solution on Kubernetes
 0:25:34
0:25:34
Ray (Episode 4): Deploying 7B GPT using Ray
 0:13:32
0:13:32
Keynote: The Future of Ray - Robert Nishihara, Anyscale
 0:37:03
0:37:03
Scaling AI Workloads with the Ray Ecosystem
 0:11:10
0:11:10
Ray Serve for IOT at Samsara
 0:34:26
0:34:26
Highly available architectures for online serving in Ray
Комментарии