filmov
tv
Implementing GPT-2 From Scratch (Transformer Walkthrough Part 2/2)
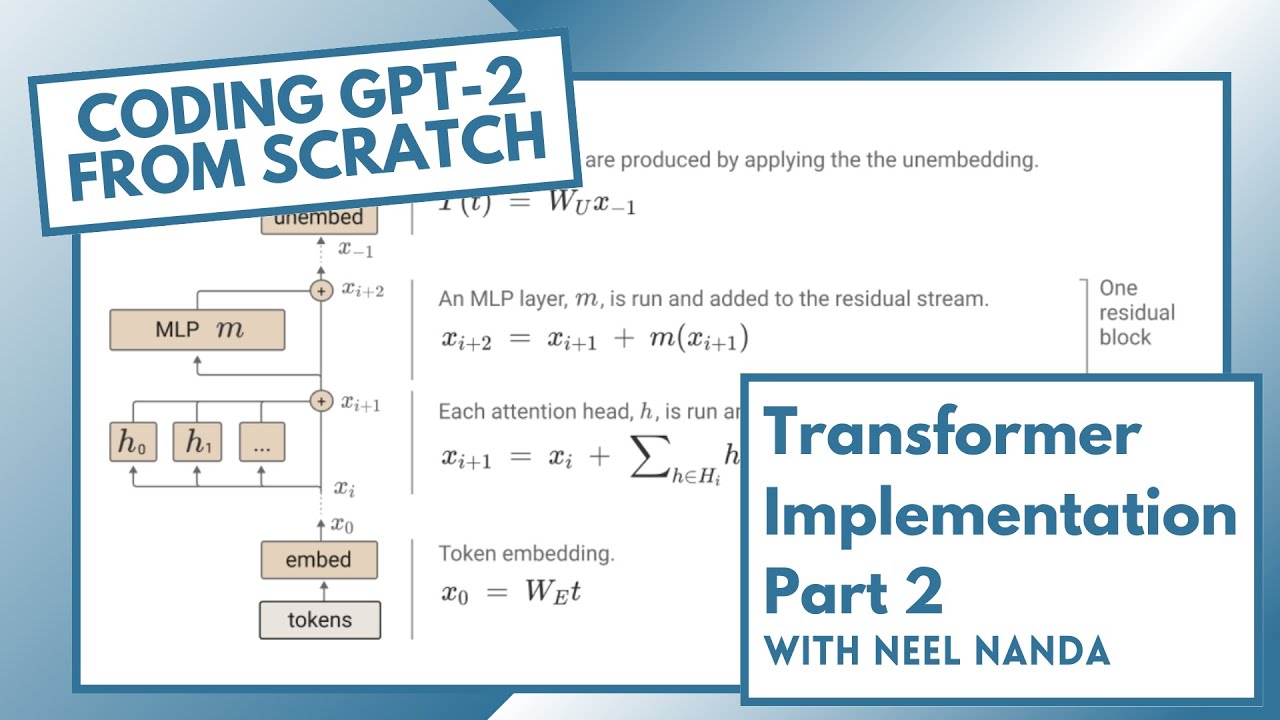
Показать описание
See part 1 here: What is a transformer?
If you enjoyed this, I expect you'd enjoy learning more about what's actually going on inside these models and how to reverse engineer them! Check out:
Further resources:
Check out these other intros to transformers for another perspective:
Timestamps:
00:00 Intro
04:01 Recap
05:03 Setup
06:04 LayerNorm
23:35 Embedding
30:07 Attention
51:22 MLP
54:00 Transformer Block
56:40 Unembedding
58:50 Full Transformer
1:01:47 Trying it out
1:11:05 Training
If you enjoyed this, I expect you'd enjoy learning more about what's actually going on inside these models and how to reverse engineer them! Check out:
Further resources:
Check out these other intros to transformers for another perspective:
Timestamps:
00:00 Intro
04:01 Recap
05:03 Setup
06:04 LayerNorm
23:35 Embedding
30:07 Attention
51:22 MLP
54:00 Transformer Block
56:40 Unembedding
58:50 Full Transformer
1:01:47 Trying it out
1:11:05 Training
 1:19:25
1:19:25
Implementing GPT-2 From Scratch (Transformer Walkthrough Part 2/2)
 1:56:20
1:56:20
Let's build GPT: from scratch, in code, spelled out.
 4:01:26
4:01:26
Let's reproduce GPT-2 (124M)
 0:27:14
0:27:14
But what is a GPT? Visual intro to transformers | Chapter 5, Deep Learning
 0:07:54
0:07:54
Text Generation with Transformers (GPT-2) In 10 Lines Of Code
 0:14:51
0:14:51
311 - Fine tuning GPT2 using custom documents
 0:41:10
0:41:10
GPT in PyTorch
 5:43:41
5:43:41
Create a Large Language Model from Scratch with Python – Tutorial
 1:02:26
1:02:26
IA382 - Seminar in Computer Engineering: 'Generalist vs Specialist Language Models' by R. ...
 0:09:11
0:09:11
Transformers, explained: Understand the model behind GPT, BERT, and T5
 0:47:54
0:47:54
Create GPT Neural Network From Scratch in 40 Minute - #pytorch #transformers #machinelearning
 0:57:10
0:57:10
Pytorch Transformers from Scratch (Attention is all you need)
 0:11:23
0:11:23
Building a GPT from scratch using PyTorch - dummyGPT
 0:11:49
0:11:49
Training GPT2 From Scratch In Hugging Face | Generative AI with Hugging Face | Ingenium Academy
 0:41:05
0:41:05
Generative Python Transformer p.5 - Training and some testing of GPT-2 model
 0:41:44
0:41:44
3- Text Generation with GPT2 Model using HuggingFace | NLP Hugging Face Project Tutorial
 0:26:29
0:26:29
Text Generation using GPT2
 0:08:38
0:08:38
Transformers: The best idea in AI | Andrej Karpathy and Lex Fridman
 0:32:57
0:32:57
Fine tuning gpt2 | Transformers huggingface | conversational chatbot | GPT2LMHeadModel
 0:24:30
0:24:30
Tutorial 1-Transformer And Bert Implementation With Huggingface
 1:03:01
1:03:01
What is a Transformer? (Transformer Walkthrough Part 1/2)
 0:43:57
0:43:57
Train GPT2 on Indian Language Dataset | DataHour by Aashay Sachdeva
 2:13:35
2:13:35
Let's build the GPT Tokenizer
 0:20:39
0:20:39
Generate Blog Posts with GPT2 & Hugging Face Transformers | AI Text Generation GPT2-Large
Комментарии