filmov
tv
Transformers: The best idea in AI | Andrej Karpathy and Lex Fridman
Показать описание
Please support this podcast by checking out our sponsors:
GUEST BIO:
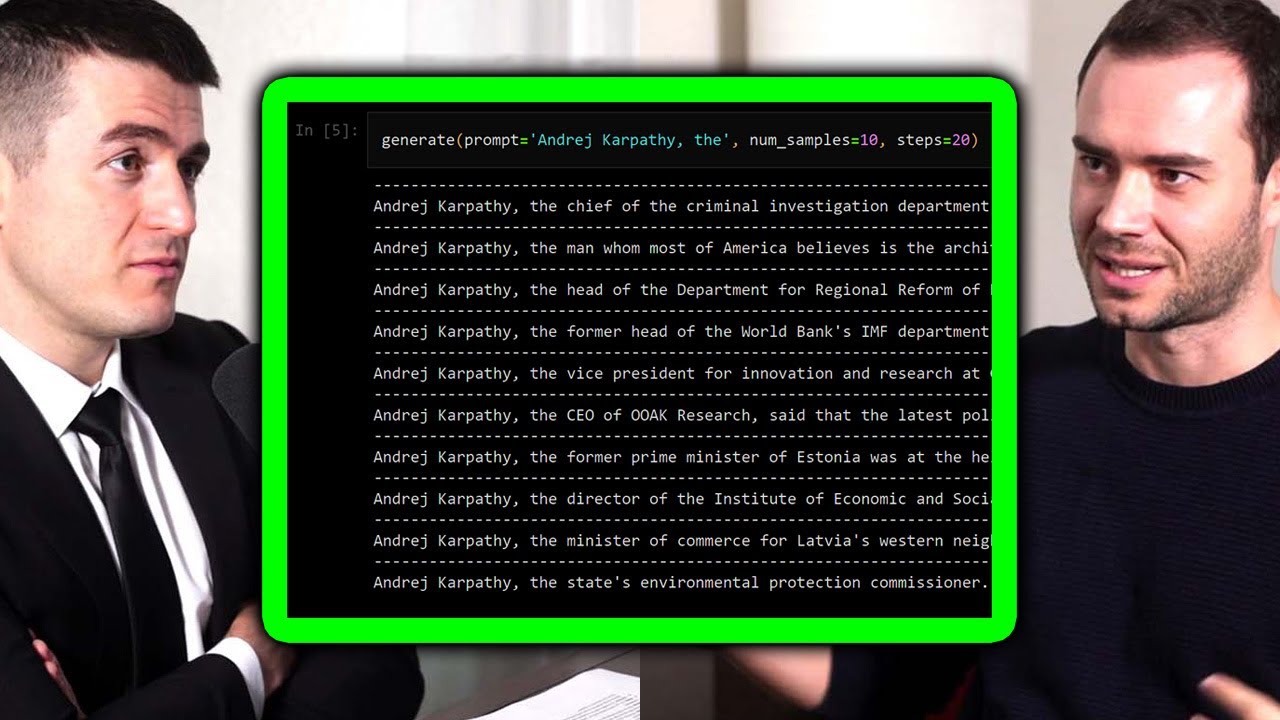
Andrej Karpathy is a legendary AI researcher, engineer, and educator. He's the former director of AI at Tesla, a founding member of OpenAI, and an educator at Stanford.
PODCAST INFO:
SOCIAL:
GUEST BIO:
Andrej Karpathy is a legendary AI researcher, engineer, and educator. He's the former director of AI at Tesla, a founding member of OpenAI, and an educator at Stanford.
PODCAST INFO:
SOCIAL:
 0:08:38
0:08:38
Transformers: The best idea in AI | Andrej Karpathy and Lex Fridman
 0:15:01
0:15:01
Illustrated Guide to Transformers Neural Network: A step by step explanation
 0:09:11
0:09:11
Transformers, explained: Understand the model behind GPT, BERT, and T5
 0:05:50
0:05:50
What are Transformers (Machine Learning Model)?
 0:27:14
0:27:14
But what is a GPT? Visual intro to transformers | Chapter 5, Deep Learning
 0:01:00
0:01:00
Transformers: Age of Extinction (2014) || Lockdown: 'You have no idea.' [4K]
 0:00:19
0:00:19
Mission: Eliminate Optimus Prime #shorts #transformers #optimusprime
 0:00:30
0:00:30
Transformers vehicles names #shorts #transformers #optimusprime
 7:59:00
7:59:00
Transformers: Rescue Bots 🔴 SEASON 4 | FULL Episodes LIVE 24/7 | Transformers Junior
 0:00:20
0:00:20
Knight Optimus was something else #shorts #transformers #optimusprime
 0:00:23
0:00:23
Marvel and DC CGI vs Transformers CGI #transformers #edits #marvel #dc
 0:00:36
0:00:36
Megatron🔥 Attitude WhatsApp Status 🔥#shorts #transformers #megatron
 0:13:25
0:13:25
Top 5 ELECTRONICS PROJECTS Using TRANSFORMERS
 0:00:50
0:00:50
Optimus Prime quotes are the best #shorts #transformers #optimusprime
 0:03:20
0:03:20
Transformers Age of Extinction (Blu Ray) Edition - Lockdown
 0:28:45
0:28:45
Transformers in NLP | GeeksforGeeks
 0:05:33
0:05:33
Optimus Prime vs Grimlock - 'Let Me Lead You' Scene | Transformers Age of Extinction (2014...
 0:00:18
0:00:18
I Can Now! | Transformers G1 | 40th Anniversary
 0:00:18
0:00:18
Sqweeks Smart Move! #edformers #shorts #transformers
 0:00:36
0:00:36
Why LOCKDOWN'S THEME SOUNDS SO GOOD 🎧 #optimusprime #Transformers #AgeOfExtinction #lockdown
 0:01:18
0:01:18
Transformers : Age of Extinction - Lockdown and Attinger Scene (1080pHD VO)
 1:19:24
1:19:24
Live -Transformers Indepth Architecture Understanding- Attention Is All You Need
 0:01:01
0:01:01
DIY Transformers Car Costume for Halloween #halloween #chainsawman #fnaf #halloweencostume #diy
 0:00:18
0:00:18
Transformers | Basics of Transformers
Комментарии