filmov
tv
Retrieval-Augmented Generation (RAG)
Показать описание
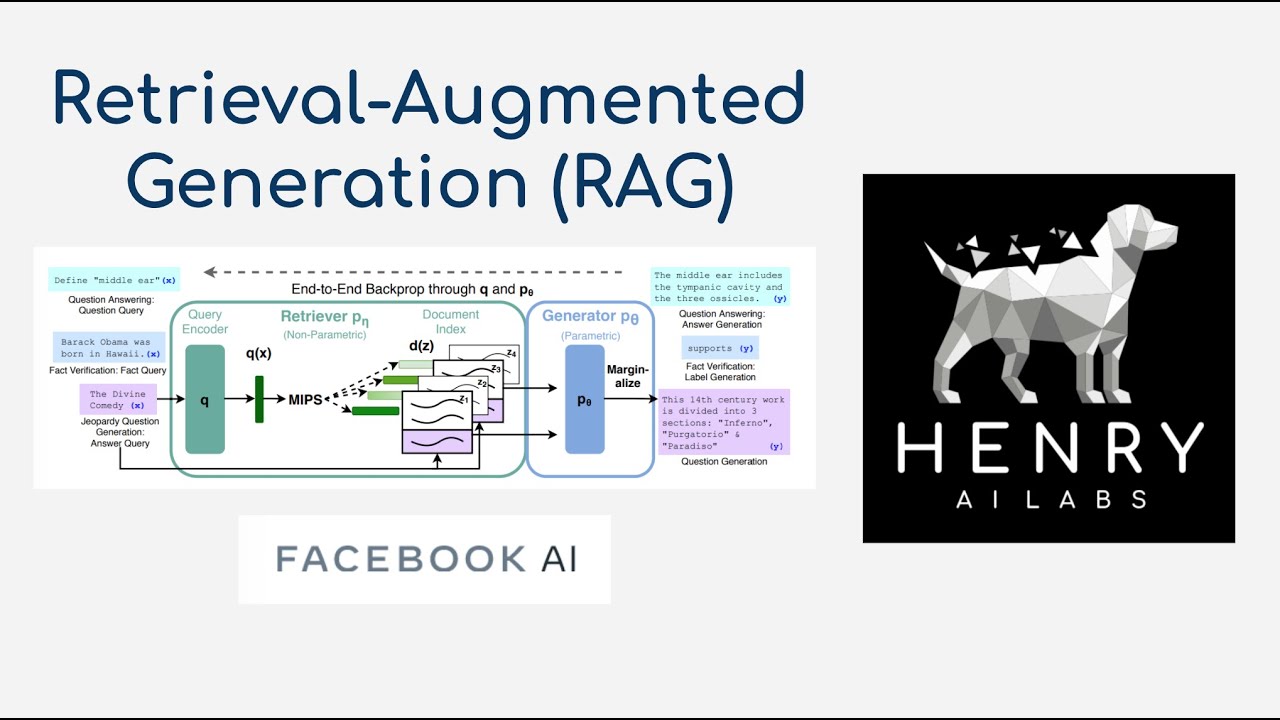
This video explains the Retrieval-Augmented Generation (RAG) model! This approach combines Dense Passage Retrieval with a Seq2Seq BART generator. This is tested out on knowledge intensive tasks like open-domain QA, jeopardy question generation, and FEVER fact verification. This looks like a really interesting paradigm for building language models that produce factually accurate generations!
Thanks for watching! Please Subscribe!
Paper Links:
Thanks for watching!
Time Stamps
0:00 Introduction
2:05 Limitations of Language Models
4:10 Algorithm Walkthrough
5:48 Dense Passage Retrieval
7:44 RAG-Token vs. RAG-Sequence
10:47 Off-the-Shelf Models
11:54 Experiment Datasets
15:03 Results vs. T5
16:16 BART vs. RAG - Jeopardy Questions
17:20 Impact of Retrieved Documents zi
18:53 Ablation Study
20:25 Retrieval Collapse
21:10 Knowledge Graphs as Non-Parametric Memory
21:45 Can we learn better representations for the Document Index?
22:12 How will Efficient Transformers impact this?
Thanks for watching! Please Subscribe!
Paper Links:
Thanks for watching!
Time Stamps
0:00 Introduction
2:05 Limitations of Language Models
4:10 Algorithm Walkthrough
5:48 Dense Passage Retrieval
7:44 RAG-Token vs. RAG-Sequence
10:47 Off-the-Shelf Models
11:54 Experiment Datasets
15:03 Results vs. T5
16:16 BART vs. RAG - Jeopardy Questions
17:20 Impact of Retrieved Documents zi
18:53 Ablation Study
20:25 Retrieval Collapse
21:10 Knowledge Graphs as Non-Parametric Memory
21:45 Can we learn better representations for the Document Index?
22:12 How will Efficient Transformers impact this?
 0:06:36
0:06:36
What is Retrieval-Augmented Generation (RAG)?
 0:05:49
0:05:49
Back to Basics: Understanding Retrieval Augmented Generation (RAG)
 0:14:08
0:14:08
A Helping Hand for LLMs (Retrieval Augmented Generation) - Computerphile
 0:11:37
0:11:37
What is RAG? (Retrieval Augmented Generation)
 0:14:31
0:14:31
Intro to RAG for AI (Retrieval Augmented Generation)
 0:49:24
0:49:24
Retrieval Augmented Generation (RAG) Explained: Embedding, Sentence BERT, Vector Database (HNSW)
 0:34:22
0:34:22
How to build Multimodal Retrieval-Augmented Generation (RAG) with Gemini
 0:09:41
0:09:41
What is Retrieval Augmented Generation (RAG) - Augmenting LLMs with a memory
 0:00:44
0:00:44
What is RAG (Retrieval-Augmented Generation)? #ai #rag #technology
 0:12:22
0:12:22
What is Retrieval-Augmented Generation (RAG)?
 0:08:03
0:08:03
RAG Explained
 0:19:52
0:19:52
How to set up RAG - Retrieval Augmented Generation (demo)
 0:03:49
0:03:49
AI Explained - AI LLM Retrieval-Augmented Generation (RAG)
 5:40:59
5:40:59
Local Retrieval Augmented Generation (RAG) from Scratch (step by step tutorial)
 0:04:34
0:04:34
Retrieval Augmented Generation (RAG) | Embedding Model, Vector Database, LangChain, LLM
 0:24:04
0:24:04
Retrieval-Augmented Generation (RAG)
 0:02:53
0:02:53
Build a Large Language Model AI Chatbot using Retrieval Augmented Generation
 0:11:01
0:11:01
Retrieval Augmented Generation (RAG) and Vector Databases [Pt 15] | Generative AI for Beginners
 2:33:11
2:33:11
Learn RAG From Scratch – Python AI Tutorial from a LangChain Engineer
 0:27:41
0:27:41
Introduction to Retrieval Augmented Generation (RAG) and Implementing with Databricks
 0:08:57
0:08:57
Was ist Retrieval Augmented Generation?
 0:00:53
0:00:53
When Do You Use Fine-Tuning Vs. Retrieval Augmented Generation (RAG)? (Guest: Harpreet Sahota)
 0:10:04
0:10:04
Understanding Retrieval Augmented Generation (RAG)
 0:08:33
0:08:33
Why Everyone is Freaking Out About RAG
Комментарии