filmov
tv
Variational Autoencoder from scratch || VAE tutorial || Developers Hutt
Показать описание
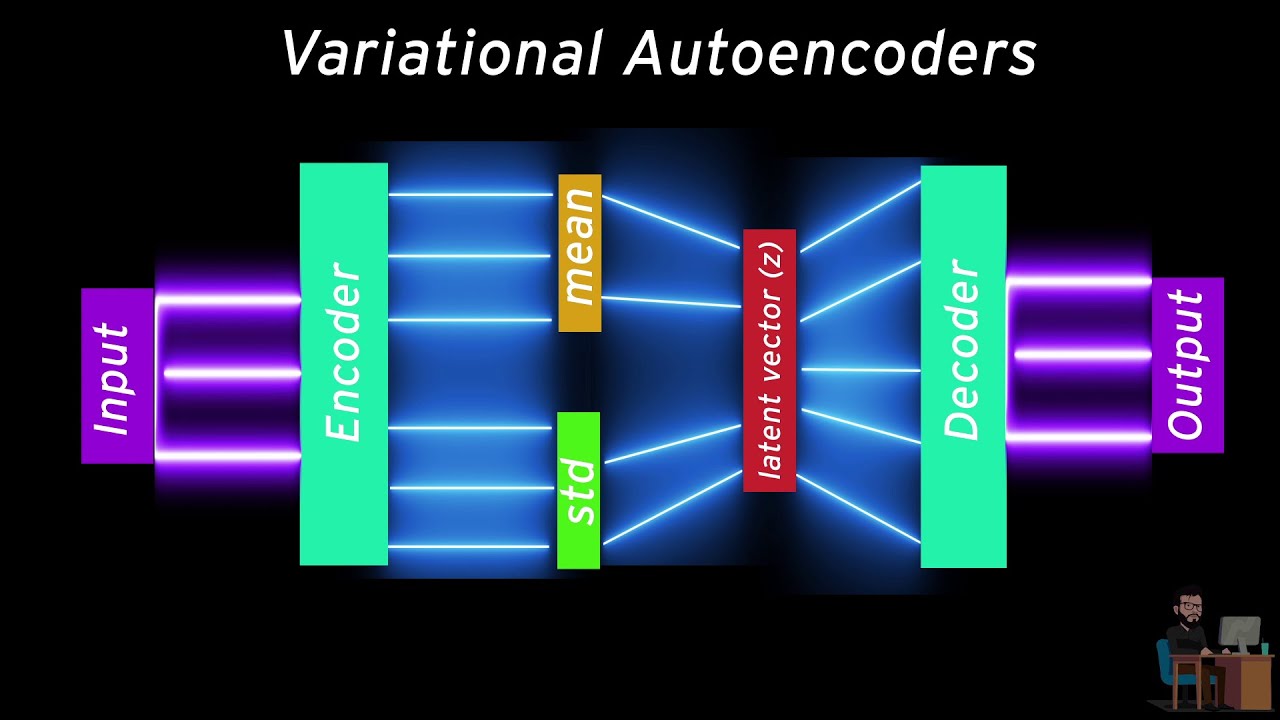
Do not directly learn from inputs, try to learn from its distribution so that you can keep track of what you're actually learning.
That is the motive behind variational Variational Autoencoders.
In this video, you'll learn how a Variational Autoencoder works and how you can make one from scratch on a dataset of your choice by using Tensorflow and Keras.
I hope you liked it.
If you have any query regarding this, kindly please comment down below and if you don't have one please try to leave your feedback, it means a lot to me.
And as always, Thanks for watching.
Download dataset from here:
I'm available for your queries, ask me at:
That is the motive behind variational Variational Autoencoders.
In this video, you'll learn how a Variational Autoencoder works and how you can make one from scratch on a dataset of your choice by using Tensorflow and Keras.
I hope you liked it.
If you have any query regarding this, kindly please comment down below and if you don't have one please try to leave your feedback, it means a lot to me.
And as always, Thanks for watching.
Download dataset from here:
I'm available for your queries, ask me at:
 0:39:34
0:39:34
Variational Autoencoder from scratch in PyTorch
 0:42:29
0:42:29
Implementing Variational Auto Encoder from Scratch in Pytorch
 0:27:12
0:27:12
Variational Autoencoder - Model, ELBO, loss function and maths explained easily!
 0:18:23
0:18:23
Variational Autoencoder from scratch || VAE tutorial || Developers Hutt
 1:19:22
1:19:22
Variational Autoencoders from Scratch!
 0:05:00
0:05:00
What are Autoencoders?
 0:06:08
0:06:08
Building a Variational Autoencoder (VAE) from Scratch in Under 5 Minutes using PyTorch
 0:57:05
0:57:05
Step-by-Step VAE Tutorial: Implementing from Scratch in TensorFlow Keras | Variational Autoencoder
 0:15:05
0:15:05
Variational Autoencoders
 0:26:17
0:26:17
Variational Auto Encoder (VAE) - Theory
 0:17:36
0:17:36
Variational Autoencoders - EXPLAINED!
 0:09:55
0:09:55
Variational Autoencoders Theory Explained | Generative AI Course
 0:23:13
0:23:13
L17.5 A Variational Autoencoder for Handwritten Digits in PyTorch -- Code Example
 0:00:06
0:00:06
Variational Autoencoder (VAE)
 0:00:38
0:00:38
Variational Autoencoder (VAE) Latent Space Visualization
 0:40:03
0:40:03
Variational AutoEncoder Paper Walkthrough
 0:29:54
0:29:54
Understanding Variational Autoencoders (VAEs) | Deep Learning
 0:17:39
0:17:39
178 - An introduction to variational autoencoders (VAE)
 0:05:24
0:05:24
L17.1 Variational Autoencoder Overview
 2:31:54
2:31:54
Introduction to Variational Autoencoders and Denoising Diffusion Probabilistic Models from Scratch
 0:20:09
0:20:09
Variational Autoencoders | Generative AI Animated
 0:43:00
0:43:00
Variational Auto-encoder with Code From Scratch
 0:59:52
0:59:52
MIT 6.S191 (2023): Deep Generative Modeling
 0:56:43
0:56:43
Building your first Variational Autoencoder with PyTorch
Комментарии