filmov
tv
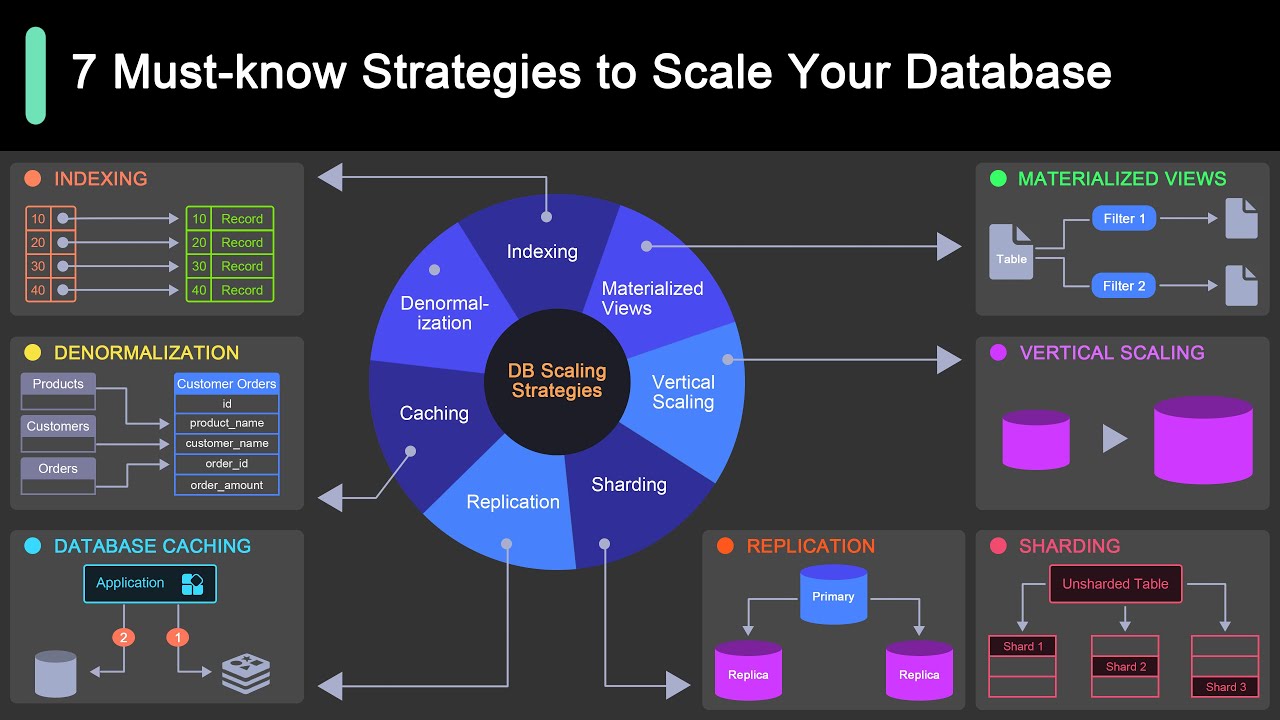
7 Must-know Strategies to Scale Your Database
Показать описание
Animation tools: Adobe Illustrator and After Effects.
Checkout our bestselling System Design Interview books:
ABOUT US:
Covering topics and trends in large-scale system design, from the authors of the best-selling System Design Interview series.
 0:08:42
0:08:42
7 Must-know Strategies to Scale Your Database
 0:14:16
0:14:16
8 Must-know Strategies to Scale Your Database
 0:04:40
0:04:40
7 Strategies to Grow Your Business | Brian Tracy
 0:12:35
0:12:35
5 Ways to Scale ANY Business
 0:05:20
0:05:20
This tool will help improve your critical thinking - Erick Wilberding
 0:13:07
0:13:07
7 Steps to Scale Any Business
 0:00:27
0:00:27
How to Answer Any Question on a Test
 0:12:50
0:12:50
Must know Scale and Arpeggio Tricks
 1:02:24
1:02:24
Top 7 Marketing Strategies to Scale over $5 Million With Dr. Kendall Price
 0:21:46
0:21:46
How to SCALE Your Business QUICKLY 🤑 Top 10 Ways to Grow FAST
 0:07:40
0:07:40
7 Proven Methods to Help Build Your Small Business to Scale
 0:21:17
0:21:17
7 Strategies to effectively scale your Facebook ad campaigns #facebookads
 0:14:47
0:14:47
How to Scale Your Business
 0:00:16
0:00:16
When is the right time to scale?
 0:00:30
0:00:30
From 6 to 7 Figures: The Proven Path to Scale 💡🚀
 0:16:41
0:16:41
8 Lessons You Should Avoid Teaching Children
 0:18:44
0:18:44
7 Minor Scales You Need to Know about
 0:00:53
0:00:53
Three Hats Technique To Scale Your Agency
 0:17:29
0:17:29
How To Scale Your Business
 0:16:29
0:16:29
How to Scale Your Business Fast
 0:12:44
0:12:44
How to Check if a User Exists Among Billions! - 4 MUST Know Strategies
 0:00:36
0:00:36
You must know these 7 tips to grow your business.
 0:16:21
0:16:21
6 Things You Need To Scale From 6 Figures To 7 Figures
 0:01:00
0:01:00
How To Scale Your eCommerce Business Beyond Eight Figures Using Microsite Strategies
Комментарии