filmov
tv
AI/ML DC Design - Part 2

Показать описание
The 0x2 Nerds continue with Petr Lapukov for part 2 of their discussion on AI/ML data center design.
 0:54:48
0:54:48
AI/ML DC Design - Part 2
 0:39:50
0:39:50
AI/ML DC Design - Part 4
 1:04:20
1:04:20
AI/ML Data Center Design - Part 1
 0:15:54
0:15:54
Next-Generation Data Center Design | Alan Duong
 0:00:24
0:00:24
Artificial intelligence
 0:02:56
0:02:56
Keysight ADS 2025 Updates: AI/ML, 6G, Load Pull
 0:23:17
0:23:17
+--400Vdc Rack Power System for ML AI Application
 0:00:19
0:00:19
Mechanical Engineering Class at IIT BHU 🔥 | ED | #iit #iitbhu #shorts #viral #jee #mechanical
 0:00:16
0:00:16
Amazing arduino project | Check description to get free money.
 0:00:16
0:00:16
Arduino project how to make a laser electronic alarm, an amazing invention DIY
 0:00:20
0:00:20
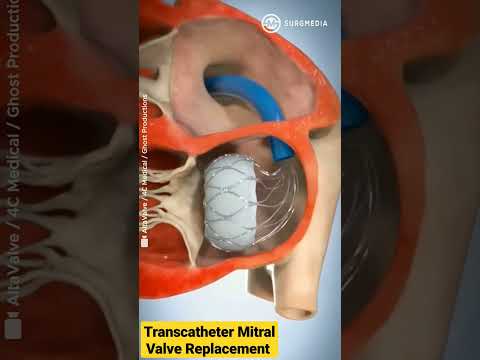
Altavalve: Transcatheter Mitral Valve Replacement (TMVR) #shorts #medical #animation
 0:45:45
0:45:45
Kickstart AI in Your Data Center with Cisco Validated Designs
 0:00:19
0:00:19
TRINITY BUILD vs CRITICAL BUILD Dyrroth
 0:00:16
0:00:16
Vehicle Accident Control Project #science #tech #project #hack
 0:00:28
0:00:28
Automatic sorting conveyor belt - Graduation project 2017 - Mechatronics | Egypt
 0:00:14
0:00:14
NEWYES Calculator VS Casio calculator
 0:00:12
0:00:12
IIT Bombay Lecture Hall | IIT Bombay Motivation | #shorts #ytshorts #iit
 0:00:09
0:00:09
Gate Smashers hai na?? Agree🤝 #shorts #gatesmashers#youtubeshorts #trending #viral
 0:00:12
0:00:12
manually writing data to a HDD...kinda #shorts
 0:00:16
0:00:16
DOCTOR vs. NURSE: $ OVER 5 YEARS #shorts
 0:00:30
0:00:30
Swedish Submachine Gun (SMG) | Carl Gustaf M/45 | How It Works
 0:00:23
0:00:23
The Only Way You Should Add Blood To LEGO Minifigures #shorts
 0:00:19
0:00:19
So you use Safari on your Mac...
 0:00:32
0:00:32
DIY mini Arduino CNC drawing machine
Комментарии