filmov
tv
An Adaptive Execution Engine For Apache Spark SQL - Carson Wang

Показать описание
"Catalyst is an excellent optimizer in SparkSQL, provides open interface for rule-based optimization in planning stage. However, the static (rule-based) optimization will not consider any data distribution at runtime. A technology called Adaptive Execution has been introduced since Spark 2.0 and aims to cover this part, but still pending in early stage. We enhanced the existing Adaptive Execution feature, and focus on the execution plan adjustment at runtime according to different staged intermediate outputs, like set partition numbers for joins and aggregations, avoid unnecessary data shuffling and disk IO, handle data skew cases, and even optimize the join order like CBO etc.. In our benchmark comparison experiments, this feature save huge manual efforts in tuning the parameters like the shuffled partition number, which is error-prone and misleading. In this talk, we will expose the new adaptive execution framework, task scheduling, failover retry mechanism, runtime plan switching etc. At last, we will also share our experience of benchmark 100 -300 TB scale of TPCx-BB in a hundreds of bare metal Spark cluster.
Session hashtag: EUdev4"
About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
Session hashtag: EUdev4"
About: Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
 0:29:33
0:29:33
An Adaptive Execution Engine For Apache Spark SQL - Carson Wang
 0:02:28
0:02:28
Adaptive Query Execution in Spark
 0:18:48
0:18:48
Advancing Spark - Crazy Performance with Spark 3 Adaptive Query Execution
 0:38:24
0:38:24
AQE in spark | Lec-19
 0:09:01
0:09:01
Adaptive Query Execution (AQE) in Spark | Spark Interview Questions
 0:17:14
0:17:14
26. Databricks | Spark | Adaptive Query Execution| Interview Question | Performance Tuning
 0:03:14
0:03:14
Demo: Spark 3 Adaptive Query Execution
 0:25:46
0:25:46
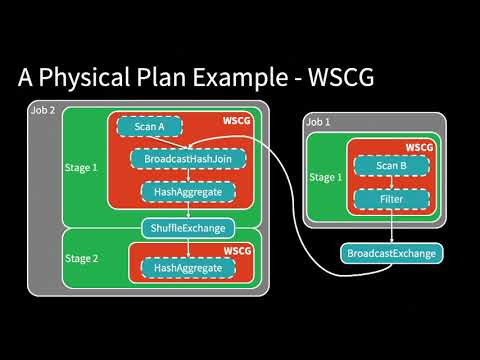
Spark SQL Adaptive Execution Unleashes The Power of Cluster (Carson Wang and Yuanjian Li)
 0:39:32
0:39:32
A Deep Dive into Query Execution Engine of Spark SQL - Maryann Xue
 0:05:48
0:05:48
Basics of Apache Spark | Spark Optimization | Adaptive Query Execution | Repartition | learntospark
 0:38:58
0:38:58
Photon for Dummies: How Does this New Execution Engine Actually Work?
 0:26:04
0:26:04
Delta Engine: High Performance Query Engine for Delta Lake | Keynote Spark + AI Summit 2020
 0:51:59
0:51:59
Tech Chat: Faster Spark SQL: Adaptive Query Execution in Databricks
 0:45:38
0:45:38
Adaptive Query Execution: Speeding Up Spark SQL at Runtime
 0:20:19
0:20:19
Query Processing and Execution in Sybase ASE | SAP ASE Tutorial
 0:06:04
0:06:04
How to Build a Linux Executable from an AUTOSAR Adaptive Model in Simulink
 0:32:41
0:32:41
Spark SQL Adaptive Execution Unleashes the Power of Cluster in Large Scale with Chenzhao Guo
 0:06:42
0:06:42
Adaptive Execution - Ford
 0:08:44
0:08:44
How To: Set Up and Configure Spark Execution Engine
 0:06:41
0:06:41
Apache Spark 3.0 and reuse subquery optimization in the Adaptive Query Execution
 0:02:13
0:02:13
P66 | Adaptive Execution of Compiled Queries
 0:21:25
0:21:25
Joe Sack (@JoeSackMSFT) - Adaptive Query Processing in SQL Server 2017 Engine
 0:11:52
0:11:52
25 AQE aka Adaptive Query Execution in Spark | Coalesce Shuffle Partitions | Skew Partitions Fix
 0:52:00
0:52:00
A Deep Dive into Query Execution Engine of Spark SQL continues -Maryann Xue
Комментарии