filmov
tv
Sorting Algorithms: Speed Is Found In The Minds of People - Andrei Alexandrescu - CppCon 2019
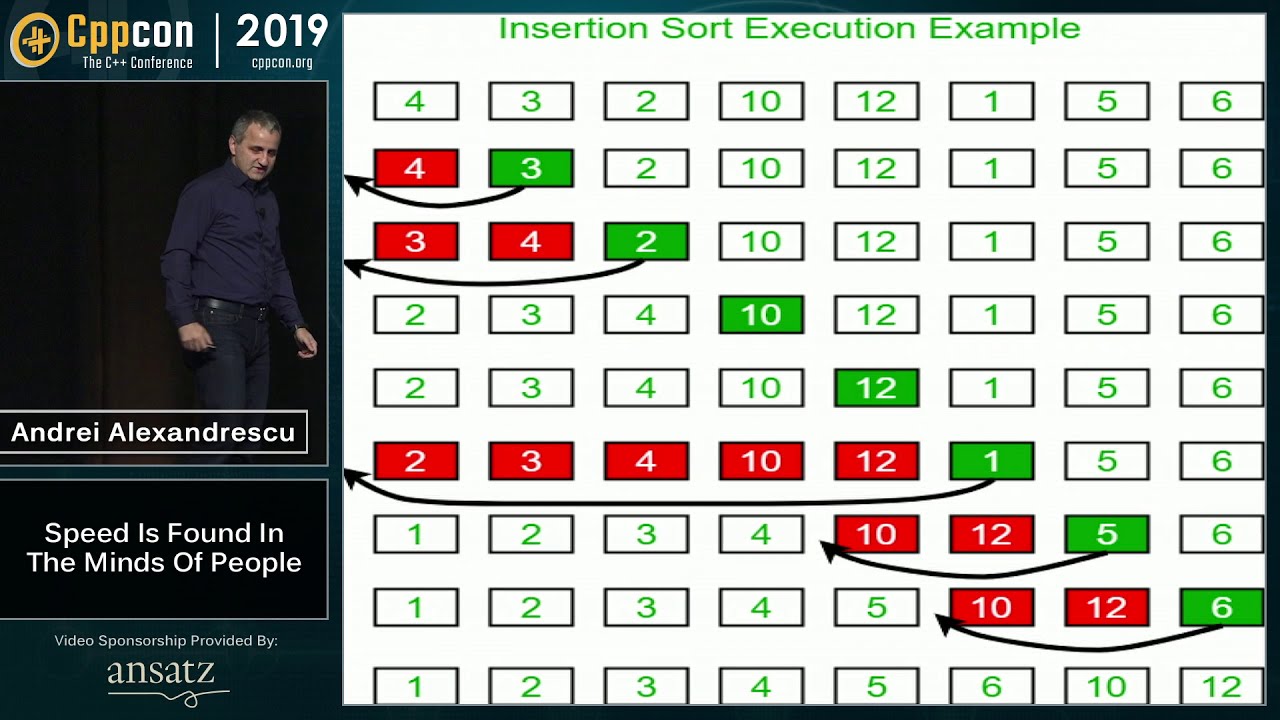
Показать описание
Sorting Algorithms: Speed Is Found In The Minds of People
In all likelihood, sorting is one of the most researched classes of algorithms. It is a fundamental task in Computer Science, both on its own and as a step in other algorithms. Efficient algorithms for sorting and searching are now taught in core undergraduate classes. Are they at their best, or is there more blood to squeeze from that stone? This talk will explore a few less known – but more allegro! – variants of classic sorting algorithms. And as they say, the road matters more than the destination. Along the way, we'll encounter many wondrous surprises and we'll learn how to cope with the puzzling behavior of modern complex architectures.
—
Andrei Alexandrescu
Andrei Alexandrescu is a researcher, software engineer, and author. He wrote three best-selling books on programming (Modern C++ Design, C++ Coding Standards, and The D Programming Language) and numerous articles and papers on wide-ranging topics from programming to language design to Machine Learning to Natural Language Processing. Andrei holds a PhD in Computer Science from the University of Washington and a BSc in Electrical Engineering from University "Politehnica" Bucharest. He is the Vice President of the D Language Foundation.
—
*-----*
*-----*
 1:29:55
1:29:55
Sorting Algorithms: Speed Is Found In The Minds of People - Andrei Alexandrescu - CppCon 2019
 0:01:33
0:01:33
We just discovered faster sorting algorithms!
 0:05:50
0:05:50
15 Sorting Algorithms in 6 Minutes
 0:08:24
0:08:24
I Made Sorting Algorithms Race Each Other
 0:10:38
0:10:38
3 Levels of Sorting Algorithms - FASTEST Comparison Sort!
 0:02:08
0:02:08
Visualization of 24 Sorting Algorithms In 2 Minutes
 0:00:38
0:00:38
I Coded Sorting Algorithms
 0:00:40
0:00:40
Quicksort vs Mergesort in 35 Seconds
 0:17:41
0:17:41
The Sorting Algorithm Olympics - Who is the Fastest of them All
 0:04:50
0:04:50
BATTLE OF THE SORTS: which sorting algorithm is the fastest? (visualization)
 0:00:49
0:00:49
Worst Sorting Algorithm Ever - #shorts
 0:10:48
0:10:48
10 Sorting Algorithms Easily Explained
 0:09:01
0:09:01
Sorting Algorithms Explained Visually
 0:00:39
0:00:39
Watch How Bubble Sort Algorithm Organizes Data in Seconds - Sorting Made Easy!
 0:44:36
0:44:36
*SEIZURE WARNING* Over 70 Sorting Algorithms in Under an Hour - 'Scrambled Tail' Inputs
 0:09:41
0:09:41
FASTEST sorting algorithm. Ever! O(N)
 0:00:20
0:00:20
Sorting Algorithms: Shell Sort
 0:26:55
0:26:55
CppCon 2018: Fred Tingaud “A Little Order: Delving into the STL sorting algorithms”
 0:00:54
0:00:54
Selection Sort - Algorithms in 60 Seconds
 0:00:39
0:00:39
Multithreaded Sorting
 0:21:44
0:21:44
Performance comparison on simple sorting algorithms
 0:04:26
0:04:26
Visualization and Comparison of Sorting Algorithms
 0:05:33
0:05:33
Ranking Sorting Algorithms (Tier List)
 0:00:11
0:00:11
5 sorting algorithms every developer should know #codinglife #shorts #softwaredeveloper
Комментарии