filmov
tv
Understanding python buffering in sys.stdout: A Guide to Unbuffered Output

Показать описание
Discover how to control stdout buffering in Python scripts to ensure immediate logging of your print statements.
---
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
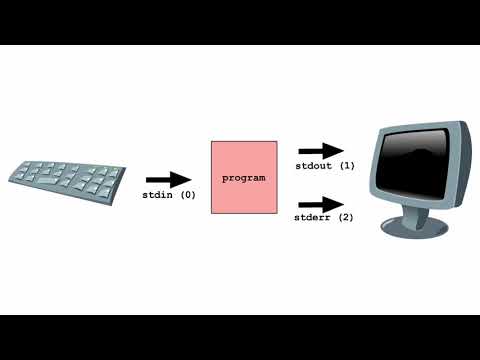
When dealing with standard output in Python, the default behavior is to buffer the output. This means that your print statements may not immediately write to your destination file – whether it's a log file or the console. This can be particularly annoying when you want to see the output of a long-running process, such as:
[[See Video to Reveal this Text or Code Snippet]]
1. Run Your Script in Unbuffered Mode
One effective way to manage buffering is to run your Python script in unbuffered mode. You can do this by using the -u option when calling your script from the command line:
[[See Video to Reveal this Text or Code Snippet]]
However, as highlighted in your question, directly applying this does not help when redirecting output to files while changing the main function is not an option. This brings us to our next solution.
2. Utilize the subprocess Module
To maintain control over output buffering while redirecting error and output streams, you can use the subprocess module. This approach allows you to run your script with the desired options and capture output in real-time:
[[See Video to Reveal this Text or Code Snippet]]
Breakdown of the Code
Import the subprocess module at the beginning.
Open your log files in write mode (w) to ensure you capture all output.
Direct stdout and stderr to the opened log files (out and err).
Why Choose This Method?
Flexibility: You can capture printed output in real-time as it occurs.
Error Handling: By redirecting stderr, you can also manage and log error messages effectively.
No changes to original functions: It allows you to maintain the integrity of your existing code while providing a solution.
Conclusion
Happy coding!
---
If anything seems off to you, please feel free to write me at vlogize [AT] gmail [DOT] com.
---
When dealing with standard output in Python, the default behavior is to buffer the output. This means that your print statements may not immediately write to your destination file – whether it's a log file or the console. This can be particularly annoying when you want to see the output of a long-running process, such as:
[[See Video to Reveal this Text or Code Snippet]]
1. Run Your Script in Unbuffered Mode
One effective way to manage buffering is to run your Python script in unbuffered mode. You can do this by using the -u option when calling your script from the command line:
[[See Video to Reveal this Text or Code Snippet]]
However, as highlighted in your question, directly applying this does not help when redirecting output to files while changing the main function is not an option. This brings us to our next solution.
2. Utilize the subprocess Module
To maintain control over output buffering while redirecting error and output streams, you can use the subprocess module. This approach allows you to run your script with the desired options and capture output in real-time:
[[See Video to Reveal this Text or Code Snippet]]
Breakdown of the Code
Import the subprocess module at the beginning.
Open your log files in write mode (w) to ensure you capture all output.
Direct stdout and stderr to the opened log files (out and err).
Why Choose This Method?
Flexibility: You can capture printed output in real-time as it occurs.
Error Handling: By redirecting stderr, you can also manage and log error messages effectively.
No changes to original functions: It allows you to maintain the integrity of your existing code while providing a solution.
Conclusion
Happy coding!
 0:01:44
0:01:44
 0:11:53
0:11:53
 0:03:29
0:03:29
 0:05:36
0:05:36
 0:03:39
0:03:39
 0:01:11
0:01:11
 0:01:35
0:01:35
 0:01:43
0:01:43
 0:00:45
0:00:45
 0:02:38
0:02:38
 0:01:26
0:01:26
 0:01:16
0:01:16
 0:00:52
0:00:52
 0:17:13
0:17:13
 0:00:52
0:00:52
 0:03:25
0:03:25
 0:00:45
0:00:45
 0:01:45
0:01:45
 0:02:17
0:02:17
 0:00:16
0:00:16
 0:06:46
0:06:46
 0:01:51
0:01:51
 0:02:09
0:02:09
 0:01:35
0:01:35