filmov
tv
Machine Learning with JAX - From Hero to HeroPro+ | Tutorial #2

Показать описание
❤️ Become The AI Epiphany Patreon ❤️
👨👩👧👦 Join our Discord community 👨👩👧👦
This is the second video in the JAX series of tutorials.
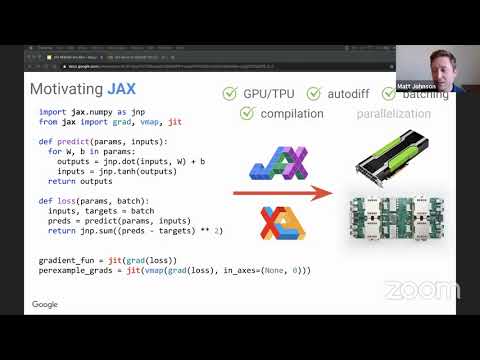
JAX is a powerful and increasingly more popular ML library built by the Google Research team. The 2 most popular deep learning frameworks built on top of JAX are Haiku (DeepMInd) and Flax (Google Research).
In this video, we continue on and learn additional components needed to train complex ML models (such as NNs) on multiple machines!
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
⌚️ Timetable:
00:00:00 My get started with JAX repo
00:01:25 Stateful to stateless conversion
00:11:00 PyTrees in depth
00:17:45 Training an MLP in pure JAX
00:27:30 Custom PyTrees
00:32:55 Parallelism in JAX (TPUs example)
00:40:05 Communication between devices
00:46:05 value_and_grad and has_aux
00:48:45 Training an ML model on multiple machines
00:58:50 stop grad, per example grads
01:06:45 Implementing MAML in 3 lines
01:08:35 Outro
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
💰 BECOME A PATREON OF THE AI EPIPHANY ❤️
If these videos, GitHub projects, and blogs help you,
consider helping me out by supporting me on Patreon!
Huge thank you to these AI Epiphany patreons:
Eli Mahler
Petar Veličković
Bartłomiej Danek
Zvonimir Sabljic
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
#jax #machinelearning #framework
👨👩👧👦 Join our Discord community 👨👩👧👦
This is the second video in the JAX series of tutorials.
JAX is a powerful and increasingly more popular ML library built by the Google Research team. The 2 most popular deep learning frameworks built on top of JAX are Haiku (DeepMInd) and Flax (Google Research).
In this video, we continue on and learn additional components needed to train complex ML models (such as NNs) on multiple machines!
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
⌚️ Timetable:
00:00:00 My get started with JAX repo
00:01:25 Stateful to stateless conversion
00:11:00 PyTrees in depth
00:17:45 Training an MLP in pure JAX
00:27:30 Custom PyTrees
00:32:55 Parallelism in JAX (TPUs example)
00:40:05 Communication between devices
00:46:05 value_and_grad and has_aux
00:48:45 Training an ML model on multiple machines
00:58:50 stop grad, per example grads
01:06:45 Implementing MAML in 3 lines
01:08:35 Outro
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
💰 BECOME A PATREON OF THE AI EPIPHANY ❤️
If these videos, GitHub projects, and blogs help you,
consider helping me out by supporting me on Patreon!
Huge thank you to these AI Epiphany patreons:
Eli Mahler
Petar Veličković
Bartłomiej Danek
Zvonimir Sabljic
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
#jax #machinelearning #framework
 0:03:24
0:03:24
JAX in 100 Seconds
 0:04:15
0:04:15
What is JAX?
 1:17:57
1:17:57
Machine Learning with JAX - From Zero to Hero | Tutorial #1
 0:10:30
0:10:30
Intro to JAX: Accelerating Machine Learning research
 0:03:31
0:03:31
Who uses JAX?
 0:03:05
0:03:05
What is Google JAX
 0:26:39
0:26:39
JAX Crash Course - Accelerating Machine Learning code!
 1:25:47
1:25:47
Coding a Neural Network from Scratch in Pure JAX | Machine Learning with JAX | Tutorial #3
 0:17:36
0:17:36
WHY JAX? Why the Hell a 3rd ML framework in 2023?
 0:09:46
0:09:46
Numpy on the GPU? Speeding up Simple Machine Learning Algorithms with JAX
 1:01:19
1:01:19
Intro to Machine Learning with JAX
 0:00:59
0:00:59
Build your first Machine Learning model with JAX!
 0:08:12
0:08:12
Demo: JAX, Flax and Gemma
 1:08:59
1:08:59
Machine Learning with JAX - From Hero to HeroPro+ | Tutorial #2
 0:02:43
0:02:43
PyTorch in 100 Seconds
 0:13:50
0:13:50
JAX: Accelerated Machine Learning Research via Composable Function Transformations in Python
 0:03:47
0:03:47
PyTorch vs TensorFlow | Ishan Misra and Lex Fridman
 0:07:05
0:07:05
Introduction to JAX
 0:15:02
0:15:02
*Fast* Python and more - Functional languages for machine learning
 1:09:58
1:09:58
JAX: accelerated machine learning research via composable function transformations in Python
 0:38:51
0:38:51
Physics-Informed Neural Networks in JAX (with Equinox & Optax)
 0:05:37
0:05:37
What is the Jax Deep Learning Framework?
 0:23:40
0:23:40
JAX: Accelerated Machine Learning Research | SciPy 2020 | VanderPlas
 0:29:49
0:29:49
Simon Pressler: Getting started with JAX
Комментарии