filmov
tv
Tesseract OCR: Extract Text From Any Image

Показать описание
Have you ever needed to extract text from an image, maybe you took a screenshot of something or you need to get a transcript of a meme, well luckily for you Tesseract OCR exists to do exactly that.
==========Support The Channel==========
==========Resources==========
=========Video Platforms==========
==========Social Media==========
==========Credits==========
🎨 Channel Art:
All my art has was created by Supercozman
#Tesseract #OpticalCharacterRecognition #TesseractOCR #Linux
🎵 Ending music
DISCLOSURE: Wherever possible I use referral links, which means if you click one of the links in this video or description and make a purchase I may receive a small commission or other compensation.
==========Support The Channel==========
==========Resources==========
=========Video Platforms==========
==========Social Media==========
==========Credits==========
🎨 Channel Art:
All my art has was created by Supercozman
#Tesseract #OpticalCharacterRecognition #TesseractOCR #Linux
🎵 Ending music
DISCLOSURE: Wherever possible I use referral links, which means if you click one of the links in this video or description and make a purchase I may receive a small commission or other compensation.
 0:11:29
0:11:29
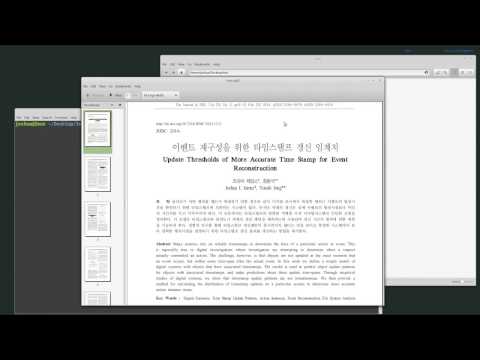
Using Tesseract-OCR to extract text from images
 0:11:09
0:11:09
Tesseract OCR: Extract Text From Any Image
 0:01:01
0:01:01
PYTHON OCR EXTRACT TEXT FROM SCANNED IMAGE PDFS | TESSERACT OCR WITH PYTHON #OCR #TESSERACT
 0:18:06
0:18:06
Extract text from images with Tesseract OCR on Windows
 0:22:21
0:22:21
Detect Text in Images with Python - pytesseract vs. easyocr vs keras_ocr
 0:00:16
0:00:16
Tesseract js | React js | OCR
 0:02:02
0:02:02
Extract Text From Images in the Browser (Using Tesseract OCR)
 0:13:02
0:13:02
How to Extract Text from Image using Python and Tesseract (OCR)
 0:29:24
0:29:24
Extract Text From Images in Python (OCR)
 0:00:25
0:00:25
Tesseract js | React js | OCR | Tesseract with React | Image To Text Conversion with React
 0:06:36
0:06:36
How to use Tesseract OCR in a Python script (pytesseract)
 0:03:19
0:03:19
Pytesseract - Convert image to text using Python in just 3 lines of code
 0:03:29
0:03:29
How to Install and Use Tesseract OCR on Windows - Optical Character Recognition
 0:00:17
0:00:17
Extract text from Image using Python: OCR 😮🐍#coding
 0:13:06
0:13:06
Using video2ocr / Tesseract-OCR to extract text from video
 0:07:03
0:07:03
How to use Tesseract OCR with Java? | Extract text from image
 0:00:20
0:00:20
With Veryfi’s advanced image detection, you can voilà your way to easy recipet data extraction! #ocr...
 0:05:48
0:05:48
Extract Text from Image with Tesseract OCR
 0:06:30
0:06:30
Python Tutorial | How to extract text from images | Tesseract-OCR Engine. | For Single File Only
 0:10:35
0:10:35
How to extract text from an image | tesseract-ocr | simplest way !!
 0:06:55
0:06:55
Extracting Text from Png files in R | Tesseract Package | OCR | R Studio
 0:18:21
0:18:21
Extract Text from Video - images | Tesseract
 0:04:44
0:04:44
Extract text from Any PDF File (even scanned ones) using OCR pytesseract in 3 SIMPLE STEPS!
 0:16:51
0:16:51
Python Extract Text from Scanned PDF | Python Extract Text from Image | Python Tesseract OCR Setup
Комментарии