filmov
tv
Lesson 3: Deep Learning 2019 - Data blocks; Multi-label classification; Segmentation

Показать описание
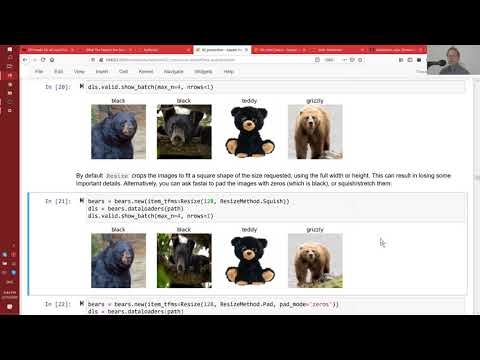
One important feature of the Planet dataset is that it is a *multi-label* dataset. That is: each satellite image can contain *multiple* labels, whereas previous datasets we've looked at have had exactly one label per image. We'll look at what changes we need to make to work with multi-label datasets.
Next, we will look at *image segmentation*, which is the process of labeling every pixel in an image with a category that shows what kind of object is portrayed by that pixel. We will use similar techniques to the earlier image classification models, with a few tweaks. fastai makes image segmentation modeling and interpretation just as easy as image classification, so there won't be too many tweaks required.
We will be using the popular Camvid dataset for this part of the lesson. In future lessons, we will come back to it and show a few extra tricks. Our final Camvid model will have dramatically lower error than an model we've been able to find in the academic literature!
What if your dependent variable is a continuous value, instead of a category? We answer that question next, looking at a keypoint dataset, and building a model that predicts face keypoints with high accuracy.
 2:04:54
2:04:54
Lesson 3: Deep Learning 2019 - Data blocks; Multi-label classification; Segmentation
 2:03:18
2:03:18
Lesson 3: Practical Deep Learning for Coders
 2:16:38
2:16:38
Lesson 3: Deep Learning 2018
 1:36:09
1:36:09
TWiML x Fast.ai Deep Learning Part 1 Review Study Group Winter 2019 - Lesson 3
 2:06:23
2:06:23
Lesson 3 - Deep Learning for Coders (2020)
 1:30:25
1:30:25
Lesson 3: Practical Deep Learning for Coders 2022
 1:58:48
1:58:48
Lesson 2: Deep Learning 2019 - Data cleaning and production; SGD from scratch
 2:17:43
2:17:43
Lesson 6: Deep Learning 2019 - Regularization; Convolutions; Data ethics
 1:23:43
1:23:43
Intro to Machine Learning: Lesson 3
 1:43:39
1:43:39
Lesson 4: Deep Learning 2019 - NLP; Tabular data; Collaborative filtering; Embeddings
 0:12:23
0:12:23
Neural Networks and Deep Learning: Crash Course AI #3
 0:51:17
0:51:17
TWiML x Fast.ai Deep Learning Part 2 Study Group - Lesson 3
 0:05:52
0:05:52
Deep Learning | What is Deep Learning? | Deep Learning Tutorial For Beginners | 2023 | Simplilearn
 2:06:41
2:06:41
Lesson 8 (2019) - Deep Learning from the Foundations
 2:19:12
2:19:12
Lesson 11 (2019) - Data Block API, and generic optimizer
 2:13:34
2:13:34
Lesson 5: Deep Learning 2019 - Back propagation; Accelerated SGD; Neural net from scratch
 2:12:50
2:12:50
Lesson 13 (2019) - Basics of Swift for Deep Learning
 1:40:12
1:40:12
Lesson 1: Deep Learning 2019 - Image classification
 0:42:36
0:42:36
3 - 4 Lesson 4 Deep Learning 2019 NLP; Tabular data; Collaborative filtering; Embeddings
 0:04:13
0:04:13
Deep Learning Lesson 3
 1:54:17
1:54:17
Lesson 2: Practical Deep Learning for Coders
 2:07:56
2:07:56
Lesson 10: Deep Learning Part 2 2018 - NLP Classification and Translation
 2:17:31
2:17:31
Lesson 7: Deep Learning 2
 0:52:41
0:52:41
TWiML x Fast.ai Machine & Deep Learning Study Group - Session 3 - 19 January 2019 - Spring 2019
Комментарии