filmov
tv
Lesson 3: Practical Deep Learning for Coders

Показать описание
UNDERFITTING & OVERFITTING
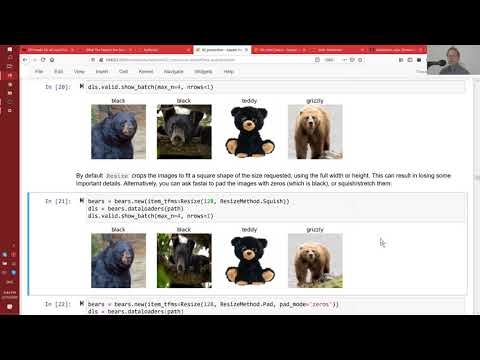
We’ve now seen a number of ways to build CNNs—it’s time to build a more complete understanding of how they work. In this lesson we review in more detail what a convolution does, and how they are combined with max pooling to create a CNN. We also learn about the softmax activation function, which is critical for getting good results in classification models (a classification model is any model that is designed to separate data items into classes, that is, into discrete groups). NB: If you’re having trouble understanding the convolution operation, you may want to skip ahead and watch the start of lesson 4, since it opens with a spreadsheet-based explanation of convolutions.
Then we delve into the most important skill in creating an effective model: dealing with overfitting and underfitting. The key is to first of all build a model that overfits (since then we know we have enough model capacity and know that we can train it) and then gradually use a number of strategies to reduce the overfitting. In this lesson the most important section is where we look at the list of techniques used to address overfitting. We suggest copying this list somewhere convenient, and refer to it often; ensure you understand what each of the steps means, and how to do them.
We then look at two particularly useful techniques to avoid overfitting: dropout, and data augmentation. We also discuss the extremely handy technique of pre-computing convolutional layers. Make sure you understand this technique before you continue, and practice it yourself, since we’ll be using it in every lesson and every notebook from here on!
We’ve now seen a number of ways to build CNNs—it’s time to build a more complete understanding of how they work. In this lesson we review in more detail what a convolution does, and how they are combined with max pooling to create a CNN. We also learn about the softmax activation function, which is critical for getting good results in classification models (a classification model is any model that is designed to separate data items into classes, that is, into discrete groups). NB: If you’re having trouble understanding the convolution operation, you may want to skip ahead and watch the start of lesson 4, since it opens with a spreadsheet-based explanation of convolutions.
Then we delve into the most important skill in creating an effective model: dealing with overfitting and underfitting. The key is to first of all build a model that overfits (since then we know we have enough model capacity and know that we can train it) and then gradually use a number of strategies to reduce the overfitting. In this lesson the most important section is where we look at the list of techniques used to address overfitting. We suggest copying this list somewhere convenient, and refer to it often; ensure you understand what each of the steps means, and how to do them.
We then look at two particularly useful techniques to avoid overfitting: dropout, and data augmentation. We also discuss the extremely handy technique of pre-computing convolutional layers. Make sure you understand this technique before you continue, and practice it yourself, since we’ll be using it in every lesson and every notebook from here on!
 1:30:25
1:30:25
Lesson 3: Practical Deep Learning for Coders 2022
 2:03:18
2:03:18
Lesson 3: Practical Deep Learning for Coders
 2:03:18
2:03:18
Lesson 3 Practical Deep Learning for Coders YouTube 720p
 6:20:30
6:20:30
Practical Deep Learning for Coders - Lesson 3 - Part 1
 2:06:23
2:06:23
Lesson 3 - Deep Learning for Coders (2020)
 11:12:32
11:12:32
Practical Deep Learning for Coders - Full Course from fast.ai and Jeremy Howard
 1:34:37
1:34:37
Lesson 4: Practical Deep Learning for Coders 2022
 2:16:38
2:16:38
Lesson 3: Deep Learning 2018
 3:00:36
3:00:36
AI Powered Programming Full Course For Beginners | Generative AI for Everyone
 4:24:01
4:24:01
Practical Deep Learning for Coders - Lesson 3 - Part 2
 1:23:43
1:23:43
Intro to Machine Learning: Lesson 3
 1:44:08
1:44:08
Practical Deep Learning for Coders - Lesson 3 - Part 3
 0:18:40
0:18:40
But what is a neural network? | Chapter 1, Deep learning
 0:55:31
0:55:31
Lesson '0': Practical Deep Learning for Coders (fast.ai)
 0:05:45
0:05:45
Neural Network In 5 Minutes | What Is A Neural Network? | How Neural Networks Work | Simplilearn
 1:16:42
1:16:42
Lesson 2: Practical Deep Learning for Coders 2022
 2:16:38
2:16:38
Intro to Deep Learning 2018 - Lesson 3
 1:42:49
1:42:49
Lesson 5: Practical Deep Learning for Coders 2022
 1:22:56
1:22:56
Practical Deep Learning for Coders: Lesson 1
 0:05:52
0:05:52
Deep Learning | What is Deep Learning? | Deep Learning Tutorial For Beginners | 2023 | Simplilearn
 1:01:19
1:01:19
Study with Me - Fast.AI's Deep Learning Course - 3. Deep Neural Networks
 1:36:55
1:36:55
Lesson 8 - Practical Deep Learning for Coders 2022
 1:36:09
1:36:09
TWiML x Fast.ai Deep Learning Part 1 Review Study Group Winter 2019 - Lesson 3
 2:15:16
2:15:16
Lesson 9: Deep Learning Foundations to Stable Diffusion
Комментарии