filmov
tv
Lessons Learned on LLM RAG Solutions
Показать описание
We’re going to do a technical deep dive into Retrieval Augmented Generation, or RAG, one of the most popular Generative AI projects. There is a ton of content about RAG applications with LLMs, but very little addresses the challenges associated with building practical applications. Today you’re going to get the inside scoop from some engineers with that experience.
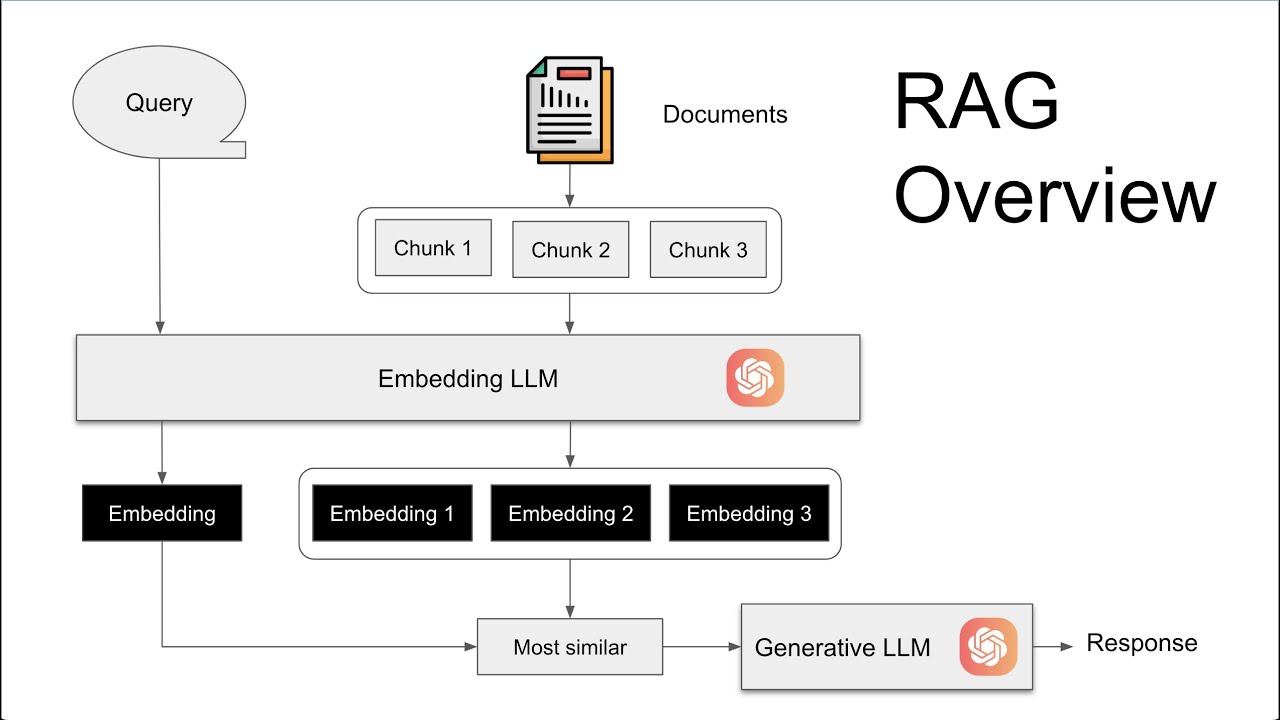
LLMs can be used to convert documents like emails or contracts to sets of vectors called embeddings. Embeddings can be used to find sets of text that are more similar in meaning. The most common business applications are semantic search, searching based on meaning and not keywords, and document Q&A. Each step presents unique challenges, and we're going to address them today.
LLMs can be used to convert documents like emails or contracts to sets of vectors called embeddings. Embeddings can be used to find sets of text that are more similar in meaning. The most common business applications are semantic search, searching based on meaning and not keywords, and document Q&A. Each step presents unique challenges, and we're going to address them today.
 0:34:31
0:34:31
Lessons Learned on LLM RAG Solutions
 0:06:36
0:06:36
What is Retrieval-Augmented Generation (RAG)?
 0:08:03
0:08:03
RAG Explained
 0:14:08
0:14:08
A Helping Hand for LLMs (Retrieval Augmented Generation) - Computerphile
 0:44:43
0:44:43
Lessons Learned from Building a Managed RAG Solution
 0:09:41
0:09:41
What is Retrieval Augmented Generation (RAG) - Augmenting LLMs with a memory
 2:33:11
2:33:11
Learn RAG From Scratch – Python AI Tutorial from a LangChain Engineer
 0:14:31
0:14:31
Intro to RAG for AI (Retrieval Augmented Generation)
 0:15:02
0:15:02
LLM Powered Chatbots Trained from PDF Manuals using RAG | Enterprises, Governments, Law Firms
 0:08:57
0:08:57
RAG vs. Fine Tuning
 0:05:34
0:05:34
How Large Language Models Work
 0:11:37
0:11:37
What is RAG? (Retrieval Augmented Generation)
 0:00:30
0:00:30
What is Retrieval Augmented Generation (RAG)?
 0:24:03
0:24:03
Build a RAG Based LLM App in 20 Minutes! | Full Langflow Tutorial
 0:05:13
0:05:13
RAG From Scratch: Part 1 (Overview)
 0:24:02
0:24:02
'I want Llama3 to perform 10x with my private knowledge' - Local Agentic RAG w/ llama3
 0:21:41
0:21:41
How to Improve LLMs with RAG (Overview + Python Code)
 0:45:16
0:45:16
Webinar 'Lessons Learned from building a Managed RAG Solution'
 0:00:58
0:00:58
How Does Rag Work? - Vector Database and LLMs #datascience #naturallanguageprocessing #llm #gpt
 0:05:51
0:05:51
Ep 30. LLM RAG Optimization Patterns
 0:05:39
0:05:39
LLM and RAG based learning tool
 0:00:59
0:00:59
RAG using Mistral AI under Minute #llm#mistralai #rag #langchain #llamas #ai #thebeginningofinfinity
 0:15:56
0:15:56
How This Vision-Based RAG System Could Save You Hours of Work!
 0:16:42
0:16:42
RAG + Langchain Python Project: Easy AI/Chat For Your Docs
Комментарии