filmov
tv
PYTHON Tutorial: How To Update/Write/ Edit /Save Data Into CSV/TXT File| Data Science | DESI ASTRO

Показать описание
1. Join this channel to get access to the perks:
🔹 Topics Covered:
✅ Loading and reading NumPy data files
✅ Modifying existing data (adding, updating, or deleting entries)
✅ Saving updated data back to a file
Why Do We Need to Update Data Files in NumPy?
When working with numerical data in Python, we often store datasets in NumPy arrays for fast and efficient processing. However, real-world data is dynamic—it changes over time, requires corrections, or needs to be expanded. Here’s why updating NumPy data files is important:
1️⃣ Correcting Errors & Cleaning Data
Sometimes, datasets contain inaccuracies, missing values, or incorrect entries that need to be fixed.
Updating allows us to replace bad values without recreating the entire dataset.
2️⃣ Appending or Modifying Data
In research, machine learning, or simulations, you might need to add new data points or update existing ones instead of generating a new dataset from scratch.
This is useful when processing time-series data or logging real-time information.
3️⃣ Improving Performance & Storage Efficiency
NumPy’s .npy format is optimized for fast loading and saving, making it preferable over text-based formats like CSV when handling large numerical datasets.
Instead of rewriting large files every time, updating specific values can save time and memory.
4️⃣ Avoiding Data Duplication
If you save a new file every time you make a small change, you end up with multiple versions of the same dataset, leading to confusion and wasted storage.
Updating data in-place helps keep a single, clean, and organized dataset.
5️⃣ Automating Data Processing Pipelines
In machine learning, scientific computing, or simulations, datasets evolve over time.
Automating the update process ensures that models and analyses always use the latest data without manual intervention.
Conclusion
Updating data files in NumPy is crucial for efficient, accurate, and scalable data management. It allows for incremental changes without recreating entire datasets, making it an essential skill for data scientists, researchers, and engineers. 🚀
🔹 Topics Covered:
✅ Loading and reading NumPy data files
✅ Modifying existing data (adding, updating, or deleting entries)
✅ Saving updated data back to a file
Why Do We Need to Update Data Files in NumPy?
When working with numerical data in Python, we often store datasets in NumPy arrays for fast and efficient processing. However, real-world data is dynamic—it changes over time, requires corrections, or needs to be expanded. Here’s why updating NumPy data files is important:
1️⃣ Correcting Errors & Cleaning Data
Sometimes, datasets contain inaccuracies, missing values, or incorrect entries that need to be fixed.
Updating allows us to replace bad values without recreating the entire dataset.
2️⃣ Appending or Modifying Data
In research, machine learning, or simulations, you might need to add new data points or update existing ones instead of generating a new dataset from scratch.
This is useful when processing time-series data or logging real-time information.
3️⃣ Improving Performance & Storage Efficiency
NumPy’s .npy format is optimized for fast loading and saving, making it preferable over text-based formats like CSV when handling large numerical datasets.
Instead of rewriting large files every time, updating specific values can save time and memory.
4️⃣ Avoiding Data Duplication
If you save a new file every time you make a small change, you end up with multiple versions of the same dataset, leading to confusion and wasted storage.
Updating data in-place helps keep a single, clean, and organized dataset.
5️⃣ Automating Data Processing Pipelines
In machine learning, scientific computing, or simulations, datasets evolve over time.
Automating the update process ensures that models and analyses always use the latest data without manual intervention.
Conclusion
Updating data files in NumPy is crucial for efficient, accurate, and scalable data management. It allows for incremental changes without recreating entire datasets, making it an essential skill for data scientists, researchers, and engineers. 🚀

How to create, write and read file in Python #Shorts

Python Pandas Tutorial (Part 5): Updating Rows and Columns - Modifying Data Within DataFrames

Python 3 Programming Tutorial - Writing to File

Python Tutorial - 13. Reading/Writing Files

Using .config() to Update Widgets - Python Tkinter GUI Tutorial #63

Write Python Code Properly!

How to Run Python Programs ( .py Files ) on Windows 11 Computer #learnpython #pythonlearning

Amazing Flower Design using Python turtle 🐢 #python #coding #funny #viral #trending #design

From Code to Canvas: Designing Stunning Art with Python Turtle 🐢🐢🐢

Amazing Rotating Python Graphics Design using Turtle 🐢 #python #pythonshorts #coding #viral #design...

I learned python so I can do this...

Python Tutorial: File Objects - Reading and Writing to Files

Python Programming Tutorial #14 - Writing to a Text File
How to create graphics using Python turtle 🐍🐢 #coding

Developer Last Expression 😂 #shorts #developer #ytshorts #uiux #python #flutterdevelopment

First python program🤞|| print 'Hello world!' in python 😇#pythonprogram #HelloWorld #print...

How to Use Google Sheets API with Python: Read, Write, Update, Delete (2025)
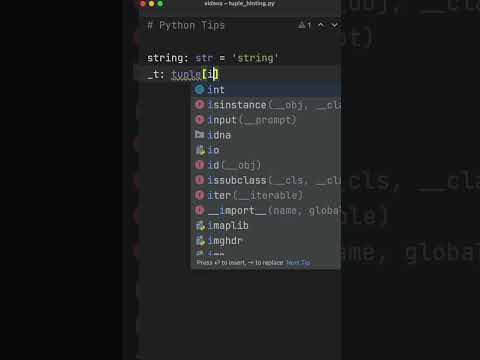
NO ONE Taught You THIS About Type Hinting In Python 👑

how to create and run python script using python IDLE #shorts #firstpythonprogram #coding #pythnidle

Python WEB SCRAPING in 30 Seconds! 🔥👨💻 #shorts

Password generator in Python!

How to turn your Python file (.py) into an .exe (Tutorial 2021)

How to write a for loop in python #shorts #programming #pythontutorial

Functions in Python are easy 📞
Комментарии