filmov
tv
Lecture 8: Norms of Vectors and Matrices

Показать описание
MIT 18.065 Matrix Methods in Data Analysis, Signal Processing, and Machine Learning, Spring 2018
Instructor: Gilbert Strang
A norm is a way to measure the size of a vector, a matrix, a tensor, or a function. Professor Strang reviews a variety of norms that are important to understand including S-norms, the nuclear norm, and the Frobenius norm.
License: Creative Commons BY-NC-SA
Instructor: Gilbert Strang
A norm is a way to measure the size of a vector, a matrix, a tensor, or a function. Professor Strang reviews a variety of norms that are important to understand including S-norms, the nuclear norm, and the Frobenius norm.
License: Creative Commons BY-NC-SA
 0:49:21
0:49:21
Lecture 8: Norms of Vectors and Matrices
 0:22:20
0:22:20
EECS - Module 8 - Induced Norms
 0:10:57
0:10:57
Numerical Methods: Vector and Matrix Norms
 0:31:21
0:31:21
Linear Algebra: Norm
 0:06:52
0:06:52
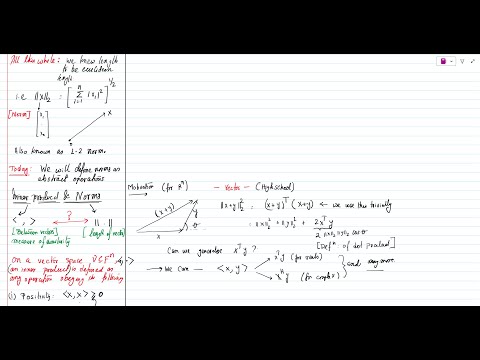
2.1 Vector norms and matrix norms
 2:43:07
2:43:07
Session 8: Inner products, vector norms, dual spaces, introduction to matrix norms
 0:47:07
0:47:07
Advanced Linear Algebra, Lecture 5.7: The norm of a linear map
 0:03:18
0:03:18
1 3 8 Submultiplicative norms
 0:06:06
0:06:06
Vector Norms - Linear Algebra
 0:09:34
0:09:34
The Lp Norm for Vectors and Functions
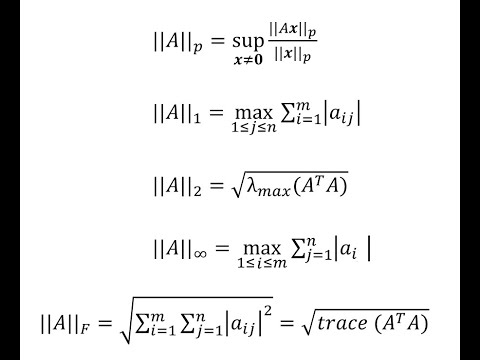 0:17:16
0:17:16
Norms of Vectors and Matrices
 0:05:14
0:05:14
MaDL - Vector and Matrix Norms
 0:03:30
0:03:30
01.3.8 Submultiplicative norms
 0:09:33
0:09:33
MATH426: Vector norms
 0:47:53
0:47:53
Lecture 8: Inner Product Spaces and Norms
 0:07:50
0:07:50
Part 8 - Norm of a Vector
 0:12:00
0:12:00
Linear Algebra, Lesson 5, Video 8: Proof of Homogeniety of Two Norm
 0:09:57
0:09:57
Matrix Norms : Data Science Basics
 0:25:45
0:25:45
1-2 Vector and matrix norms
 0:04:01
0:04:01
3.3.7-Linear Algebra: Vector and Matrix Norms
 0:09:16
0:09:16
1.3.4 Induced matrix norms
 0:05:15
0:05:15
What is Norm in Machine Learning?
 0:02:57
0:02:57
norm of a vector in R2
 0:05:42
0:05:42
01.2.3 The 2 norm
Комментарии