filmov
tv
python requests get html after javascript

Показать описание
Certainly! Retrieving HTML content after JavaScript has executed using Python is often referred to as "web scraping with dynamic content." To achieve this, you can use a combination of tools, including the requests library for making HTTP requests and a headless browser or a tool like Selenium to render and execute JavaScript.
Here's a step-by-step tutorial on how to accomplish this task:
Make sure you have the necessary packages installed. You can install them using pip:
You need to download a WebDriver executable compatible with your browser. In this example, we'll use the Chrome WebDriver. Download it from ChromeDriver, and place the executable in a directory accessible from your Python environment.
Now, let's create a Python script that uses requests and Selenium to get HTML content after JavaScript execution.
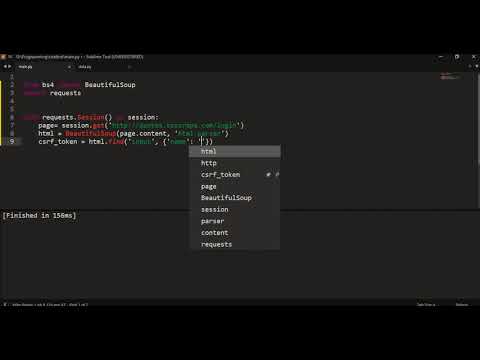
This example uses a headless browser for simplicity, but you can explore other options based on your requirements. Additionally, consider using a library like BeautifulSoup to parse and navigate through the HTML content after retrieval.
ChatGPT
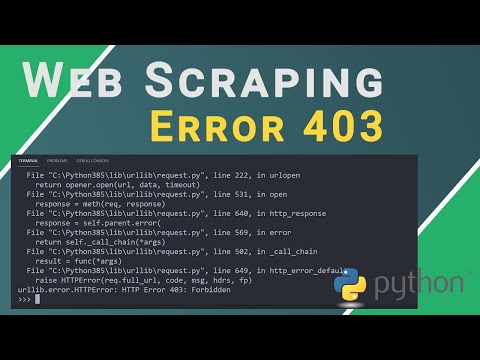
When working with web scraping or automation, you may encounter websites that load content dynamically using JavaScript. The traditional requests library alone won't capture this dynamic content because it only retrieves the static HTML. To handle such scenarios, you'll need to use a more sophisticated approach. In this tutorial, we'll explore how to use Python with the requests library and Selenium to obtain HTML content after JavaScript execution.
Make sure you have the following installed:
Install the required packages using the following commands:
Additionally, you need to download the appropriate WebDriver for your browser. For this tutorial, we'll use the Chrome WebDriver, which you can find here.
Replace "path/to/chromedriver" with the actual path to your Chrome WebDriver executable.
Here's a step-by-step tutorial on how to accomplish this task:
Make sure you have the necessary packages installed. You can install them using pip:
You need to download a WebDriver executable compatible with your browser. In this example, we'll use the Chrome WebDriver. Download it from ChromeDriver, and place the executable in a directory accessible from your Python environment.
Now, let's create a Python script that uses requests and Selenium to get HTML content after JavaScript execution.
This example uses a headless browser for simplicity, but you can explore other options based on your requirements. Additionally, consider using a library like BeautifulSoup to parse and navigate through the HTML content after retrieval.
ChatGPT
When working with web scraping or automation, you may encounter websites that load content dynamically using JavaScript. The traditional requests library alone won't capture this dynamic content because it only retrieves the static HTML. To handle such scenarios, you'll need to use a more sophisticated approach. In this tutorial, we'll explore how to use Python with the requests library and Selenium to obtain HTML content after JavaScript execution.
Make sure you have the following installed:
Install the required packages using the following commands:
Additionally, you need to download the appropriate WebDriver for your browser. For this tutorial, we'll use the Chrome WebDriver, which you can find here.
Replace "path/to/chromedriver" with the actual path to your Chrome WebDriver executable.
 0:04:54
0:04:54
 0:25:01
0:25:01
 0:05:55
0:05:55
 0:12:58
0:12:58
 0:56:27
0:56:27
 0:06:58
0:06:58
 0:08:46
0:08:46
 0:07:32
0:07:32
 0:00:26
0:00:26
 0:03:21
0:03:21
 0:07:34
0:07:34
 0:00:32
0:00:32
 0:13:55
0:13:55
 0:05:38
0:05:38
 0:10:57
0:10:57
 0:22:28
0:22:28
 0:04:33
0:04:33
 0:06:45
0:06:45
 0:14:00
0:14:00
 0:18:45
0:18:45
 0:13:41
0:13:41
 0:04:21
0:04:21
 0:06:52
0:06:52
 0:20:32
0:20:32