filmov
tv
What are Distributed CACHES and how do they manage DATA CONSISTENCY?

Показать описание
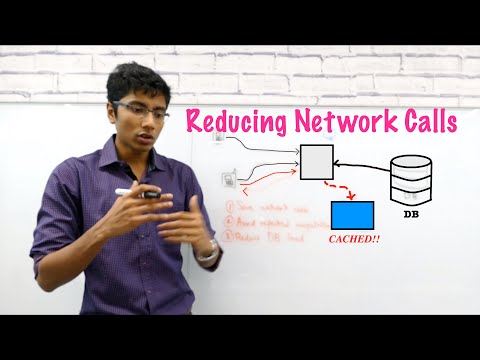
Caching in distributed systems is an important aspect for designing scalable systems. We first discuss what is a cache and why we use it. We then talk about what are the key features of a cache in a distributed system.
The cache management policies of LRU and Sliding Window are mentioned here. For high performance, the cache eviction policy must be chosen carefully. To keep data consistent and memory footprint low, we must choose a write-through or write-back consistency policy.
Cache management is important because of its relation to cache hit ratios and performance. We talk about various scenarios in a distributed environment.
System Design Video Course:
00:00 Who should watch this video?
00:18 What is a cache?
02:14 Why not store everything in a cache?
03:00 Cache Policies
04:49 Cache Evictions and Thrashing
05:52 Consistency Problems
06:32 Local Caches
07:49 Global Caches
08:56 Where should you place a cache?
09:35 Cache Write Policies
11:38 Hybrid Write Policy?
13:10 Thank you!
A complete course on how systems are designed. Along with video lectures, the course has architecture diagrams, capacity planning, API contracts, and evaluation tests.
You can follow me on:
References:
#SystemDesign #Caching #DistributedSystems
The cache management policies of LRU and Sliding Window are mentioned here. For high performance, the cache eviction policy must be chosen carefully. To keep data consistent and memory footprint low, we must choose a write-through or write-back consistency policy.
Cache management is important because of its relation to cache hit ratios and performance. We talk about various scenarios in a distributed environment.
System Design Video Course:
00:00 Who should watch this video?
00:18 What is a cache?
02:14 Why not store everything in a cache?
03:00 Cache Policies
04:49 Cache Evictions and Thrashing
05:52 Consistency Problems
06:32 Local Caches
07:49 Global Caches
08:56 Where should you place a cache?
09:35 Cache Write Policies
11:38 Hybrid Write Policy?
13:10 Thank you!
A complete course on how systems are designed. Along with video lectures, the course has architecture diagrams, capacity planning, API contracts, and evaluation tests.
You can follow me on:
References:
#SystemDesign #Caching #DistributedSystems
 0:13:29
0:13:29
What are Distributed CACHES and how do they manage DATA CONSISTENCY?
 0:05:48
0:05:48
Cache Systems Every Developer Should Know
 0:34:34
0:34:34
System Design Interview - Distributed Cache
 0:04:00
0:04:00
Distributed Cache explained - Software Architecture Introduction (part 3)
 0:37:41
0:37:41
19. System Design: Distributed Cache and Caching Strategies | Cache-Aside, Write-Through, Write-Back
 0:06:19
0:06:19
What is Redis Cache?
 0:13:25
0:13:25
Caching Architectures | Microservices Caching Patterns | System Design Primer | Tech Primers
 0:34:10
0:34:10
Redis system design | Distributed cache System design
 0:05:03
0:05:03
Cache | System Design Fundamentals
 0:20:03
0:20:03
Distributed Cache System Design - Part I | What is Distributed Caching?
 0:52:41
0:52:41
Enterprise Grade Performance with Distributed Cache
 0:08:44
0:08:44
Distributed Caching
 0:01:12
0:01:12
Introducing Stashed Distributed Cache
 0:26:19
0:26:19
What is Distributed cache and example of Map Reduce wordcount example program Distributed cache
 0:07:45
0:07:45
What is Distributed Cache Explained? Caching Architectures | Introduction to Distributed Database
 0:08:08
0:08:08
System design: Cache. Where can caches be located? Local cache/ global cache and distributed cache.
 0:07:20
0:07:20
Lesson 77 - Caching Topologies: Distributed Cache
 1:11:08
1:11:08
Boosting your applications with distributed caches/datagrids by Katia Aresti
 0:06:12
0:06:12
Redis Cache Course video #1l Distributed Cache in Asp.NETCore6.0| What is Distributed Caching?
 0:07:01
0:07:01
distributed cache and transparent integration
 0:07:33
0:07:33
Distributed cache in Hadoop | Explained in example with Full MapReduce code
 0:02:30
0:02:30
demo distributed cache
 0:12:01
0:12:01
Distributed Cache Writes: What You Have To Know | Systems Design Interview 0 to 1 With Ex-Google SWE
 0:04:13
0:04:13
Distributed cache | Hadoop Interview questions
Комментарии